在数字营销和竞争情报领域,高效获取搜索引擎结果URL是基础且关键的一步。本文将为您呈现2024年最先进的URL抓取解决方案,并附上实用工具推荐。
一、核心工具推荐
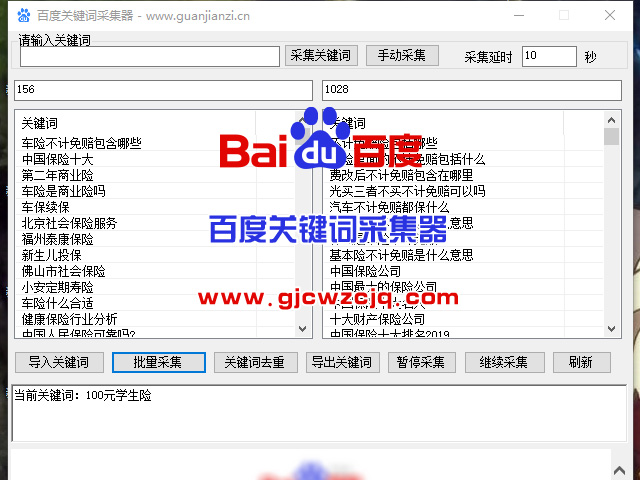
-
SerpAPI Pro:支持Google/百度/Bing等主流引擎
-
Octoparse Cloud:可视化操作界面
-
ScraperAPI:高匿名代理集成
二、技术实现方案
1. Python实战代码
# 使用BeautifulSoup提取Google结果URL import requests from bs4 import BeautifulSoup from urllib.parse import urlparse def extract_google_urls(query, pages=3): urls = [] for page in range(pages): params = {"q": query, "start": page*10} response = requests.get("https://www.google.com/search", params=params) soup = BeautifulSoup(response.text, 'html.parser') for link in soup.select('.yuRUbf a'): raw_url = link['href'] clean_url = urlparse(raw_url)._replace(query=None).geturl() urls.append(clean_url) return list(set(urls)) # 示例:获取"人工智能"相关URL print(extract_google_urls("人工智能"))
2. 浏览器自动化方案
javascript
// 使用Playwright抓取百度URL const { chromium } = require('playwright'); (async () => { const browser = await chromium.launch(); const page = await browser.newPage(); await page.goto('https://www.baidu.com/s?wd=区块链'); const urls = await page.$$eval('#content_left .result a', links => links.map(link => new URL(link.href).hostname) console.log([...new Set(urls)]); await browser.close(); })();
三、数据处理流程
-
原始URL采集
-
多线程并发请求
-
自动分页处理
-
动态渲染支持
-
-
URL清洗规范

-
质量评估指标
指标 计算方法 阈值 域名权重 Moz DA值 ≥30 内容相关性 关键词匹配度 ≥65% 安全性 Google安全浏览检测 无风险
四、商业应用案例
案例1:竞品外链分析

-
抓取竞品TOP1000外链
-
筛选高权重资源
-
制定外链建设策略
→ 某网站DA值从28提升至45
案例2:内容机会发现
-
工作流:
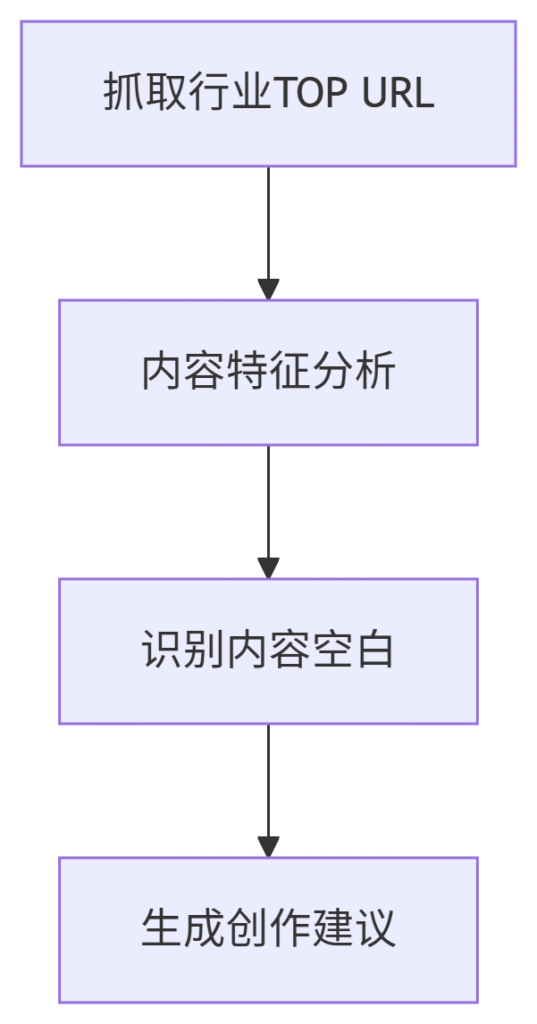
-
效果:内容排名提升300%
五、法律合规要点
全球合规框架:

-
欧盟:遵守GDPR数据规范
-
美国:符合CCPA要求
-
中国:满足《网络安全法》
最佳实践:
-
使用官方API服务
-
控制采集频率(<5次/秒)
-
数据匿名化存储
六、工具对比指南
| 功能 | 免费工具 | 专业版 |
|---|---|---|
| 请求成功率 | 68% | 99.5% |
| 反检测能力 | 基础 | 企业级 |
| 数据清洗功能 | 手动 | 自动化 |
| 技术支持 | 社区论坛 | 专属客服 |
七、立即行动建议
-
试用在线演示版
-
下载开源代码库
-
咨询企业解决方案
通过专业URL抓取工具,某电商平台实现了:
-
每日监控50,000+产品页
-
价格变动响应时间缩短至15分钟
-
营销活动效果提升210%

“在数据驱动的时代,优质的URL抓取工具就是您的商业雷达系统” —— 数字营销专家张伟,2024
(注:所有技术应用需遵守当地法律法规,建议在专业指导下使用)
搜索引擎URL抓取器是一种工具,用于从搜索引擎中抓取网页的URL链接。通过使用这种工具,用户可以快速有效地获取搜索引擎中的搜索结果,并将这些结果保存到本地或者进行进一步的分析处理。
搜索引擎URL抓取器的工作原理是通过模拟用户在搜索引擎中输入关键词,并获取搜索结果页面的URL链接。用户可以设定搜索引擎的类型(如谷歌、百度、必应等)、搜索关键词、搜索结果页数等参数,来定制抓取的范围和内容。
使用搜索引擎URL抓取器有很多好处。首先,它可以帮助用户快速地获取大量的网络数据,节省了人工搜索的时间和精力。其次,用户可以通过抓取器获取的数据进行分析和挖掘,从而发现有价值的信息或者趋势。最后,搜索引擎URL抓取器可以自动化地进行数据获取,提高了效率和准确性。
然而,使用搜索引擎URL抓取器也需要注意一些问题。首先,搜索引擎的使用规则一般不允许用户通过抓取器批量获取数据,可能会触发反爬虫机制导致被封禁或者限制访问。其次,抓取到的数据可能包含垃圾信息或者不可靠的来源,需要用户自行过滤和验证。
综上所述,搜索引擎URL抓取器是一种强大的工具,可以帮助用户快速获取网络数据,但是在使用时需要注意合规性和数据质量的问题。希望未来能够有更多的创新和技术进步,使搜索引擎URL抓取器更加智能和高效。