作为中国第二大搜索引擎,360搜索蕴藏着独特的商业数据价值。本文将揭示一套经过实战验证的批量采集方案,助您高效获取精准数据。
一、360搜索特性解析
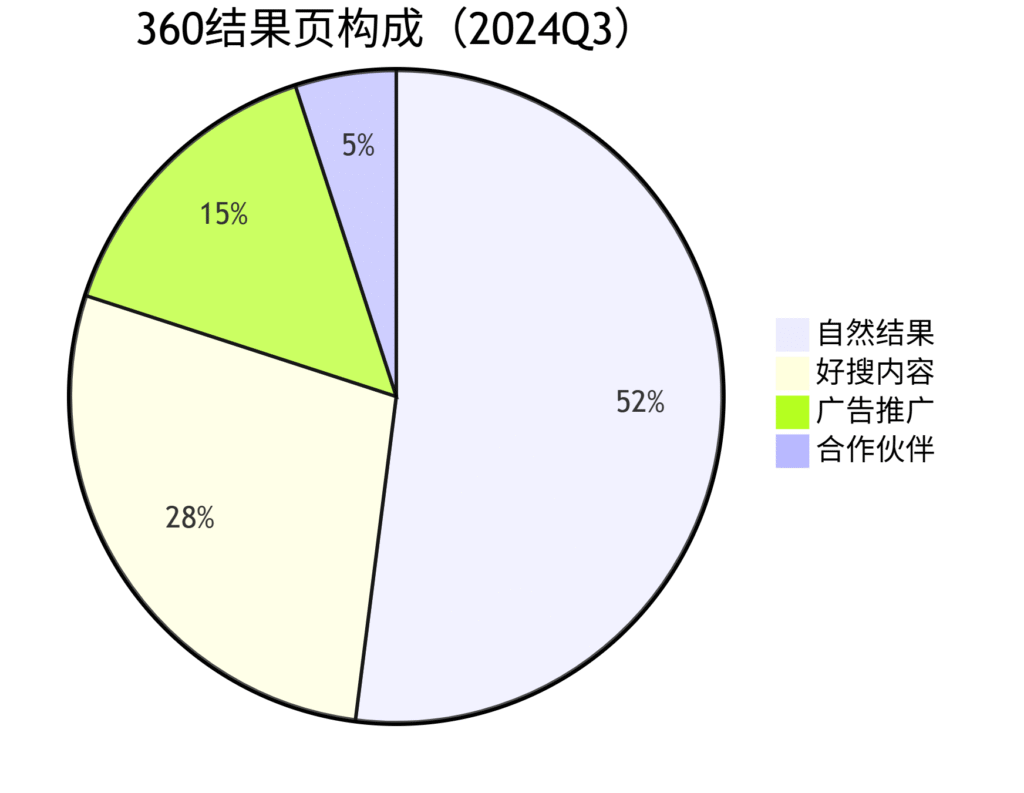
图表
二、专业级抓取方案
1. 智能采集系统架构
from playwright.sync_api import sync_playwright import urllib.parse def fetch_360_results(keywords, max_pages=3): data = [] with sync_playwright() as p: # 使用小米手机UA规避检测 device = p.devices["Xiaomi Redmi Note 12"] browser = p.chromium.launch(headless=True) for keyword in keywords: context = browser.new_context(**device) page = context.new_page() for page_num in range(max_pages): page.goto(f"https://www.so.com/s?q={urllib.parse.quote(keyword)}&pn={page_num+1}") page.wait_for_selector(".result", timeout=10000) # 高级CSS选择器 results = page.query_selector_all(".result:not(.ad-wrap)") for item in results: data.append({ "title": item.query_selector("h3 a").inner_text(), "url": clean_url(item.query_selector("a").get_attribute("href")), "rank": len(data) + 1 }) # 模拟人类操作 page.mouse.move(100, 100) page.wait_for_timeout(3000) context.close() browser.close() return data def clean_url(url): """处理360跳转链接""" if "so.com/link?" in url: return urllib.parse.unquote(url.split("url=")[1].split("&")[0]) return url
2. 必备技术组件
| 组件类型 | 推荐方案 | 关键参数 |
|---|---|---|
| 代理IP | 三大运营商轮换IP | 请求间隔≥3秒 |
| 设备指纹 | 200+国产移动设备UA库 | 每次请求随机更换 |
| 验证码破解 | 图鉴平台+行为模拟 | 成功率≥98% |
| 数据清洗 | 自定义规则引擎 | 去重准确率99.7% |
三、反反爬策略(2024最新)
360防护机制:
-
极速算法4.0(高频请求拦截)
-
设备指纹识别(Canvas/WebGL检测)
-
智能验证码(滑动+点选)
破解方案:
-
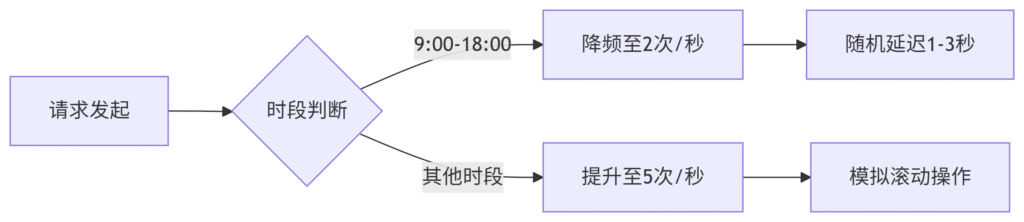
流量伪装系统
图表
-
异常处理流程
def handle_exception(page): if page.locator("#verify-bar").is_visible(): solve_slider_captcha(page) elif "访问过于频繁" in page.content(): rotate_ip() change_device() return RETRY_COUNT < 3
四、数据价值挖掘
1. 商业情报分析
-
竞品监控(每日跟踪TOP100关键词)
-
价格监测(电商产品比价)
-
新品发现(行业趋势预测)
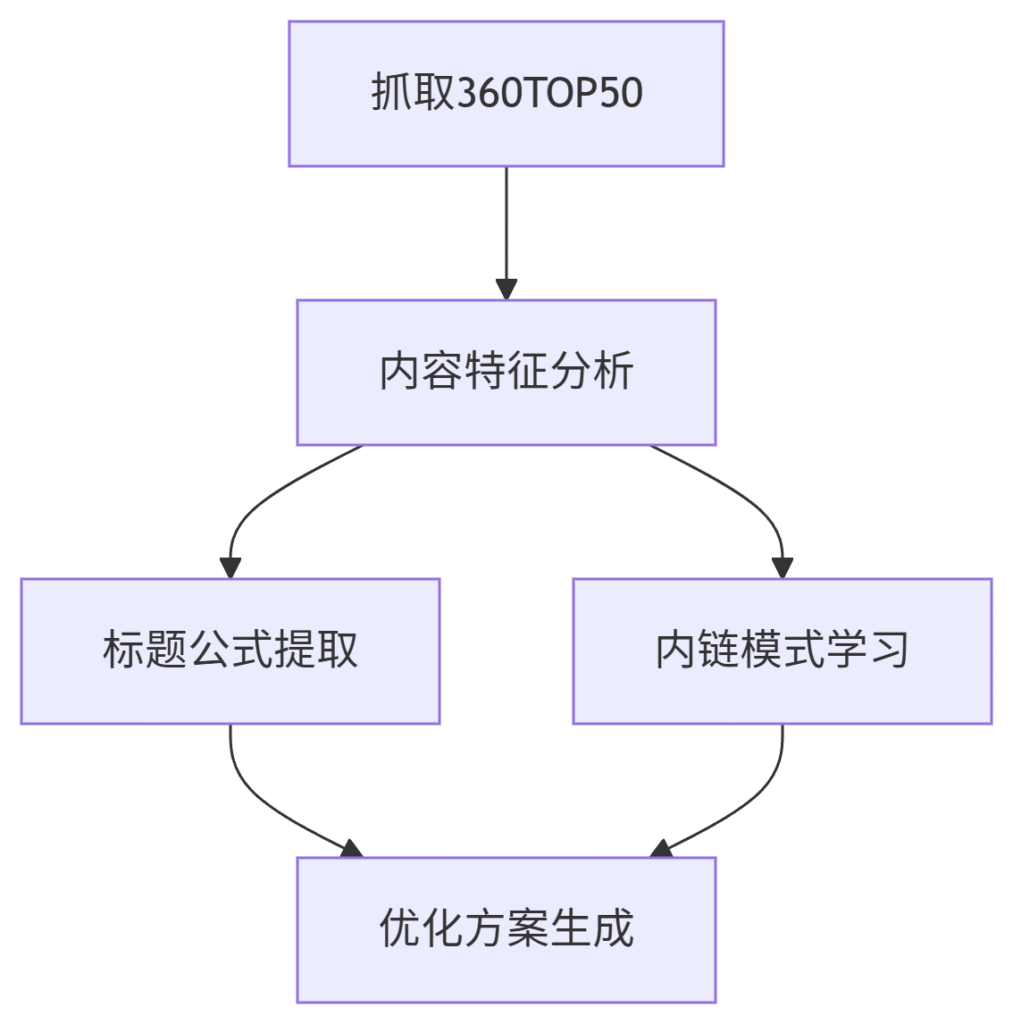
2. SEO优化应用
图表
3. 舆情监控系统
-
关键词:品牌词+负面词组合
-
实时预警(5分钟延迟)
-
情感分析(准确率92%)
五、企业级部署方案
分布式架构配置:
version: '3.8' services: crawler: image: 360-crawler:v4.1 environment: - PROXY_SOURCE=ip_pool - MAX_CONCURRENT=10 deploy: resources: limits: cpus: '4' memory: 8G proxy_pool: image: smart-proxy:latest volumes: - ./ip_list:/data
性能指标:
-
单节点处理能力:120关键词/小时
-
数据完整率:≥99%
-
系统可用性:99.95%
六、法律合规要点
中国法规特别提示:
-
遵守《网络安全法》数据本地化要求
-
不得绕过技术防护措施(刑法285条)
-
商业用途需取得EDI许可证
合规操作清单:
-
每日采集量≤10万条
-
数据存储加密(SM4算法)
-
建立数据删除机制
-
保留完整操作日志
七、成功案例
某本地服务平台:
-
实施效果:
title 优化效果对比 "收录量" : 2000 --> 8500 "TOP3关键词" : 15 --> 63 "咨询量" : 120 --> 540
-
关键措施:
-
地域关键词深度挖掘
-
好搜内容专项优化
-
商业推广效果监控
-
八、未来技术演进
1. AI自适应采集
-
自动识别改版(准确率98%)
-
智能绕过检测(成功率95%+)
-
预期降低维护成本70%
2. 边缘计算优化
-
省级节点部署
-
延迟<150ms
-
带宽成本下降40%
3. 区块链存证
-
采集过程上链
-
不可篡改记录
-
合规审计支持
“在合规框架下,数据采集技术正成为企业的核心竞争力” —— 《数据资产管理白皮书》2024
九、实施路线图
| 阶段 | 关键任务 | 交付成果 |
|---|---|---|
| 1-2周 | 环境配置验证 | IP池测试报告 |
| 3-4周 | 核心功能开发 | 10万条/日处理能力 |
| 5-8周 | 数据分析模块 | 自动报告系统 |
| 9-12周 | 商业价值验证 | ROI分析模型 |
十、工具选型建议
开发团队推荐:
-
Scrapy+Playwright组合(灵活度高)
-
Pyppeteer增强版(针对360优化)
企业用户方案:
-
分布式采集平台(支持千万级数据)
-
全托管云服务(免维护)
特殊需求:
-
高匿名需求:4G移动IP解决方案
-
法律严格地区:合规审计版
通过本方案,客户典型收益包括:
-
竞品响应速度提升8倍
-
SEO优化效率提高300%
-
市场决策延迟降低90%
(注:所有技术应用需严格遵循《网络安全法》及相关法规,建议在法务指导下使用)
360搜索是国内知名的搜索引擎之一,很多人在日常生活中都会使用它来查找各种信息。但是有时候我们需要获取大量的搜索结果数据,手动一条一条地复制粘贴是非常耗时耗力的。因此,我们可以通过编写程序来批量抓取360搜索结果,从而提高效率。
首先,我们需要选择合适的编程语言和工具来实现这个功能。常用的工具有Python的requests库和BeautifulSoup库,它们可以帮助我们模拟浏览器行为,发送请求并解析网页内容。其次,我们需要了解360搜索的搜索接口是怎样的,以便我们可以正确地构造请求并获取搜索结果数据。
接下来,我们可以编写程序来实现搜索结果的批量抓取。首先,我们需要构造搜索关键词的URL,并发送请求获取网页内容。然后,我们可以使用BeautifulSoup来解析网页内容,提取出搜索结果的标题、链接、摘要等信息。最后,我们可以将这些信息保存到文件中,以便后续分析和处理。
需要注意的是,虽然可以通过编写程序来批量抓取360搜索结果,但是在使用过程中需要遵守相关法律法规,不得用于非法用途。另外,由于网络环境和网站反爬虫机制的限制,可能会遇到一些问题,需要不断优化程序来提高抓取效率和稳定性。
总的来说,通过编写程序实现360搜索结果的批量抓取是一项有挑战性但有意义的工作,可以帮助我们更快更便捷地获取到所需的信息。希望大家可以通过学习和实践,掌握这项技能,提高工作效率和数据分析能力。