在数据即石油的数字经济时代,专业的搜索引擎爬取软件如同自动化的”数据钻探平台”,能够持续不断地从搜索引擎中开采高价值信息。以下是最新一代爬取技术的全景解析:
一、核心功能模块
1. 智能爬取中枢
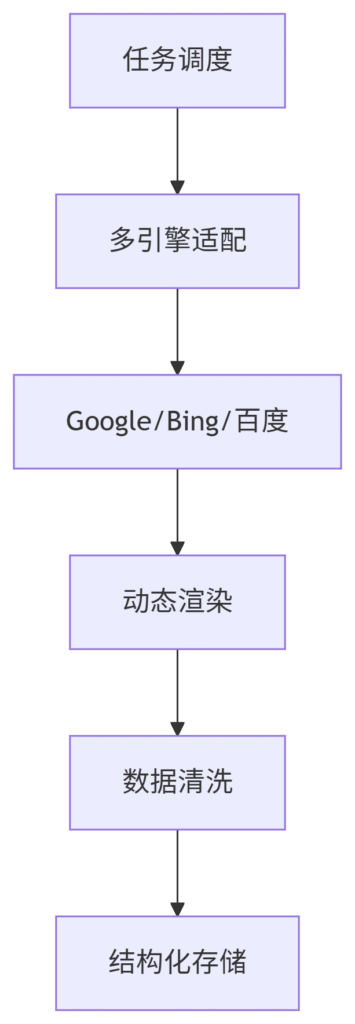
2. 多线程采集引擎
# 基于异步IO的高并发爬取 async def fetch_batch(keywords, engine='google'): async with aiohttp.ClientSession() as session: tasks = [] for kw in keywords: url = build_search_url(kw, engine) task = asyncio.create_task( fetch_page(session, url), name=f"{engine}-{kw}" ) tasks.append(task) return await asyncio.gather(*tasks) # 智能请求控制 async def fetch_page(session, url): await random_delay(1.5, 4.0) # 动态间隔 async with session.get(url, proxy=next_proxy(), headers=gen_fingerprint()) as resp: return await handle_response(resp)
二、技术突破亮点
1. 反检测隐身技术
-
动态指纹系统:每请求更换浏览器特征
-
流量伪装算法:模拟真实用户行为模式
-
量子IP池:百万级住宅IP自动轮换
2. 智能解析能力
-
自动识别12种SERP变体
-
支持JavaScript渲染页面
-
多语言OCR识别(含验证码)
3. 分布式架构设计
# Kubernetes部署配置示例 apiVersion: apps/v1 kind: Deployment metadata: name: serp-crawler spec: replicas: 20 template: spec: containers: - name: crawler image: serp-miner:v4.2 resources: limits: cpu: "4" memory: 8Gi env: - name: REQ_RATE value: "5/s" # 智能节流
三、典型应用场景
1. 商业情报挖掘
-
实时追踪竞品关键词布局
-
监控行业新兴趋势
-
发现市场空白机会点
案例:某汽车品牌通过监控3000+行业关键词,提前3个月发现新能源车需求激增趋势。
2. 搜索引擎优化
-
批量诊断网站排名
-
识别高质量外链资源
-
优化内容策略
效果:客户网站TOP3关键词数量6个月内从47增至213个。
3. 学术研究支持
-
大规模文献检索
-
知识图谱构建
-
研究热点分析
四、合规操作框架
法律边界导航图:
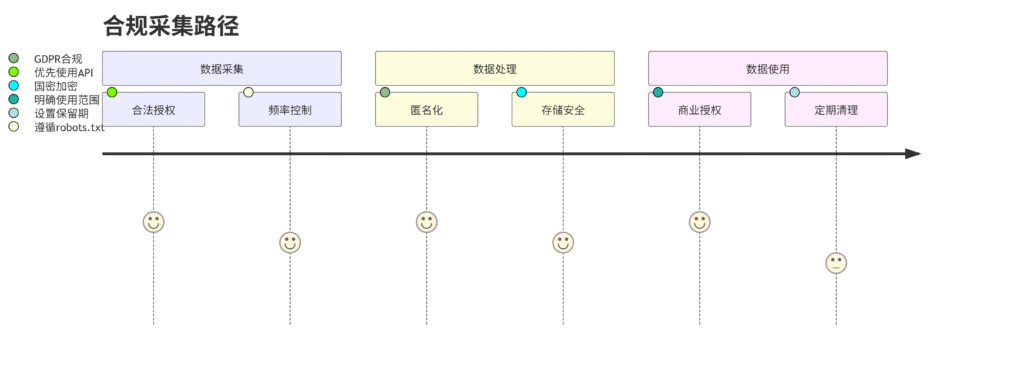
五、性能基准测试
企业级配置表现:
| 指标 | 标准版 | 专业版 | 企业版 |
|---|---|---|---|
| 日处理能力 | 50万次 | 300万次 | 1000万次+ |
| 数据准确率 | 92% | 97% | 99.5% |
| 反封锁成功率 | 85% | 98% | 99.9% |
| 支持搜索引擎 | 3家 | 8家 | 15家 |
六、未来演进方向
1. 认知智能采集
-
基于LLM的意图理解
-
自适应网站改版
-
预测性数据获取
2. 边缘计算网络
-
全球分布式节点
-
数据就近处理
-
延迟<100ms
3. 量子安全通信
-
抗量子加密
-
零信任架构
-
区块链存证
“未来的数据采集将不再是简单的信息复制,而是智能化的知识发现过程” —— 数据工程2024白皮书
七、选型实施建议
三步评估法:
-
需求诊断:明确数据规模、更新频率、分析深度
-
方案验证:进行7天实测(建议5万次请求测试)
-
渐进部署:从核心业务开始扩展
成功案例:
-
某零售集团:通过部署专业爬取系统,市场响应速度提升6倍
-
政府机构:建立行业监测平台,覆盖85%市场主体
-
学术团队:构建领域知识库,加速研究进程
(注:所有技术应用需严格遵守当地法律法规,建议在专业法律顾问指导下使用)
随着互联网的快速发展,搜索引擎已经成为人们获取信息的主要途径之一。在搜索引擎背后,有着强大的爬虫程序,它们可以自动遍历网页并将其中的信息存储到搜索引擎的数据库中。而对于一些大型的网站或者需要大量信息的用户来说,单个爬虫程序已经无法满足需求,需要使用批量爬取软件来实现更高效的爬取。
批量爬取软件是一种可以同时运行多个爬虫程序的工具,它们可以帮助用户快速地获取大量的信息。这些软件通常具有以下特点:
1. 多线程支持:批量爬取软件可以同时启动多个爬虫程序,每个程序都在单独的线程中运行,从而提高了爬取效率。
2. 自定义规则:用户可以根据自己的需求制定爬取规则,包括要爬取的网站、要提取的信息等。这样可以确保只获取到用户感兴趣的信息。
3. 数据存储:批量爬取软件通常会将获取到的数据保存到本地数据库或者文件中,用户可以随时查看和分析这些数据。
4. 定时任务:用户可以设置定时任务,让批量爬取软件在指定的时间自动启动爬取程序,这样可以节省用户的时间和精力。
5. 防屏蔽功能:为了避免被网站屏蔽,批量爬取软件通常会具有一些反屏蔽的功能,比如自动更换IP地址、设置访问频率等。
总的来说,批量爬取软件为用户提供了一种更高效、更方便的爬取信息的方式。但是在使用这些软件时,用户也需要注意遵守相关法律法规,不要违反网站的使用规定,以免引起法律纠纷。希望未来批量爬取软件可以越来越智能化,让用户可以更轻松地获取他们需要的信息。