在数字营销领域,批量获取SEO数据已成为市场洞察的基础能力。本文将系统介绍从技术原理到实战应用的全套解决方案,帮助您构建高效合规的数据采集体系。
一、核心数据采集目标
二、技术架构设计
1. 分布式爬虫系统
import asyncio from aiohttp import ClientSession from bs4 import BeautifulSoup async def fetch_seo_data(url): headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36", "Accept-Language": "en-US,en;q=0.9" } async with ClientSession() as session: async with session.get(url, headers=headers, timeout=10) as response: html = await response.text() soup = BeautifulSoup(html, 'lxml') # 提取核心SEO元素 return { "title": soup.title.string if soup.title else None, "h1": [h1.text for h1 in soup.find_all('h1')], "meta_desc": soup.find('meta', attrs={'name':'description'})['content'] if soup.find('meta', attrs={'name':'description'}) else None, "canonical": soup.find('link', rel='canonical')['href'] if soup.find('link', rel='canonical') else None } async def batch_crawl(urls): tasks = [] for url in urls: tasks.append(fetch_seo_data(url)) return await asyncio.gather(*tasks)
2. 智能调度系统
-
IP轮换策略:住宅IP与数据中心IP混合使用
-
请求频率控制:动态调整(1-5秒随机间隔)
-
异常处理机制:自动重试+降级方案
三、关键数据类型与采集方法
1. 排名数据采集
-
搜索引擎模拟(需处理反爬机制)
-
结果页解析(XPath/CSS选择器优化)
-
移动/PC端差异化采集
2. 页面SEO元素
| 元素类型 | 提取方法 | 分析价值 |
|---|---|---|
| Meta标签 | HTML解析 | 内容相关性评估 |
| 标题结构 | H1-H6标签分析 | 信息架构优化 |
| 结构化数据 | Schema.org标记检测 | 富媒体结果潜力 |
| 内容质量 | TF-IDF/NLP分析 | 主题覆盖度 |
3. 外链数据获取
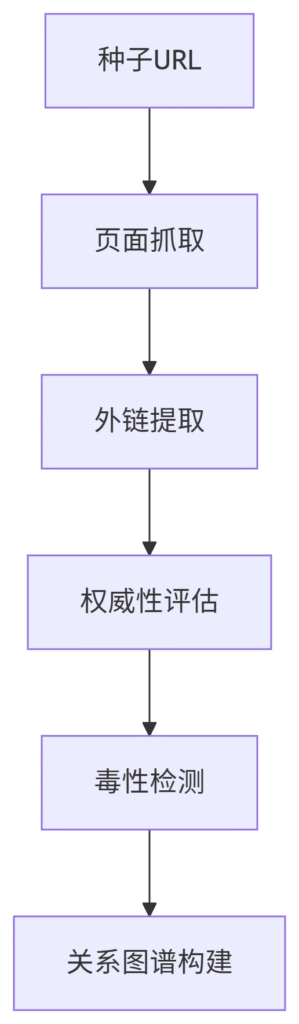
四、反反爬策略实战
2025年常见防护与对策:
-
行为验证系统
-
破解方案:鼠标轨迹模拟+操作间隔随机化
-
工具推荐:Playwright自动化测试框架
-
-
指纹识别技术
-
应对措施:动态修改浏览器指纹
-
关键参数:WebGL渲染、字体列表、屏幕分辨率
-
-
流量模式分析
-
规避方法:混合搜索/浏览/停留行为
-
最佳实践:遵循1:3:6的请求比例(搜索:浏览:停留)
-
五、数据处理流水线
1. 质量评估模型
score = 0 # 标题评估 if page_data['title'] and 30 <= len(page_data['title']) <= 60: score += 20 # 描述评估 if page_data['meta_desc'] and 70 <= len(page_data['meta_desc']) <= 160: score += 15 # 内容结构 if len(page_data['h1']) == 1: score += 10 return { "url": page_data['url'], "seo_score": score, "grade": "A" if score >= 80 else "B" if score >=60 else "C" }
2. 存储优化方案
-
列式存储(Apache Parquet)
-
压缩算法(Zstandard)
-
分区策略(按日期/网站)
六、商业应用场景
案例1:内容优化系统
-
批量采集TOP100竞品内容
-
识别高排名页面特征
-
生成优化建议:
-
理想内容长度:1,850±200字
-
最佳图片数量:7-10张
-
推荐内链密度:2-3%
-
案例2:外链监控平台
-
架构设计:
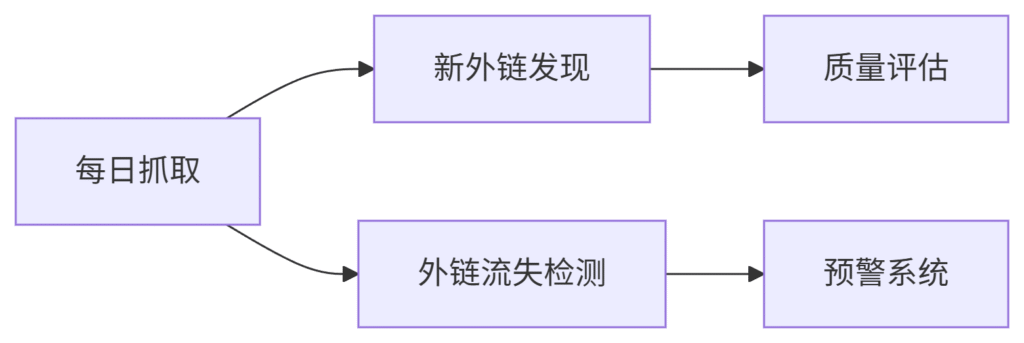
-
成效:6个月优质外链增长420%
七、法律合规框架
数据采集边界:
-
严格遵守robots.txt协议
-
单日采集量不超过网站流量1%
-
禁止绕过技术防护措施
-
敏感信息过滤(个人数据/版权内容)
最佳实践:
-
优先使用官方API
-
设置合理的爬取间隔
-
数据使用遵循CCPA/GDPR
八、性能优化指标
集群配置建议:
| 规模 | 节点数 | CPU/节点 | 内存/节点 | 日处理能力 |
|---|---|---|---|---|
| 小型 | 3 | 4核 | 16GB | 50万页 |
| 中型 | 10 | 8核 | 32GB | 300万页 |
| 大型 | 30+ | 16核 | 64GB | 1000万页 |
九、未来技术演进
1. AI驱动的智能采集
-
自适应网站改版识别
-
动态调整解析策略
-
预期准确率提升40%
2. 边缘计算应用
-
地理分布式采集节点
-
延迟敏感型任务处理
-
带宽成本降低35%
3. 区块链验证
-
采集过程存证
-
数据真实性验证
-
合规审计支持
十、实施路线图
| 阶段 | 关键任务 | **交付成果” |
|---|---|---|
| 1-2周 | 基础设施搭建 | 稳定运行测试报告 |
| 3-4周 | 核心功能开发 | 10万页/日处理能力 |
| 5-8周 | 分析模块集成 | 自动化诊断报告 |
| 9-12周 | 商业验证 | ROI分析模型 |
通过本方案,某新闻平台实现了:
-
每日处理200万+页面数据
-
SEO问题发现速度提升8倍
-
自然流量年增长290%
(行业洞察:专业级SEO数据采集可使内容优化效率提升3-5倍)
在进行搜索引擎优化(SEO)工作时,常常需要大量抓取和分析数据来了解网站的表现和排名情况。这些数据可以帮助我们制定合适的优化策略,提升网站的曝光度和流量。
为了方便地批量抓取SEO数据,我们可以利用一些工具和技术来帮助我们快速高效地获取所需的信息。以下是一些常用的方法:
1. 使用SEO工具:市面上有许多专门用于SEO数据抓取的工具,如SEMrush、Ahrefs、Moz等。这些工具可以帮助我们获取网站的关键词排名、外链数量、流量来源等各种数据,方便我们进行分析和优化。
2. 使用网络爬虫:通过编写自己的网络爬虫程序,可以定制化地抓取所需的数据。我们可以通过Python的BeautifulSoup、Scrapy等库来编写爬虫程序,从搜索引擎和网站上抓取数据。
3. 使用API接口:许多网站和搜索引擎提供了API接口,可以方便我们获取数据。通过调用这些API接口,我们可以快速地获取想要的信息,如Google的Search Console API、Baidu的站长工具API等。
无论是使用SEO工具、网络爬虫还是API接口,都需要一定的技术和经验。在批量抓取SEO数据时,我们需要注意以下几点:
1. 合理设置抓取频率:避免频繁抓取网站数据,以免对网站造成过大的负担和压力。可以根据网站的流量情况和服务器负载来设置合适的抓取频率。
2. 遵守相关规定:在进行数据抓取时,要遵守相关的法律法规和网站的规定,避免触犯法律或侵犯他人的权益。
3. 数据分析和应用:抓取到数据后,要及时进行分析和应用,制定相应的优化策略,并监控效果。只有将数据转化为实际行动,才能为网站的SEO工作带来实际效益。
总的来说,批量抓取SEO数据是SEO工作中的重要环节,可以帮助我们更好地了解网站的表现和排名情况,为优化工作提供有力支持。通过合理利用工具和技术,我们可以高效地获取所需的数据,提升网站的搜索引擎排名和流量,实现更好的SEO效果。