在数字营销领域,内容数据是新的石油。本文将为您呈现一套完整的批量抓取解决方案,从技术实现到商业应用的全链条方法论。
一、SEO内容抓取黄金三角
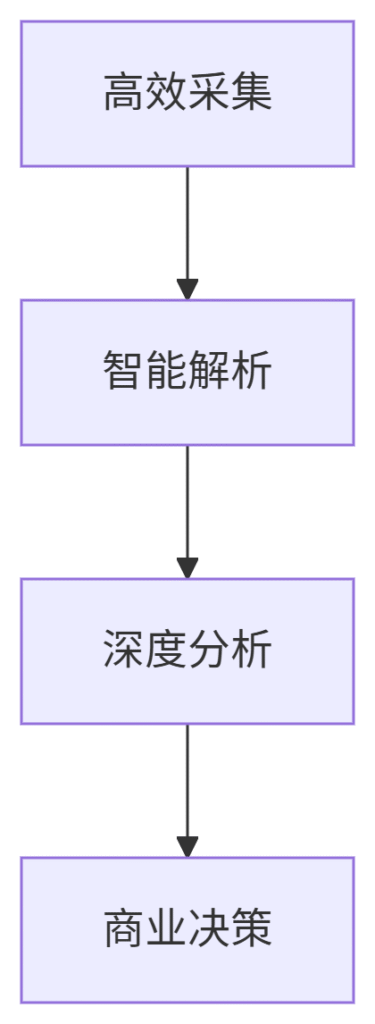
二、2024顶级工具库
1. 企业级解决方案
-
ContentKing Enterprise
-
实时监控10万+网页
-
自动检测内容变更
-
智能推荐优化点
-
定价:$999/月起
-
2. 开发者神器组合
# 基于Scrapy+Readability的内容提取 import scrapy from readability import Document class SEOContentSpider(scrapy.Spider): name = 'seo_content' def start_requests(self): urls = ['https://example.com/blog'] # 初始URL列表 for url in urls: yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): doc = Document(response.text) yield { 'url': response.url, 'title': doc.title(), 'content': doc.summary(), 'word_count': len(doc.summary().split()), 'headers': response.xpath('//h1|//h2|//h3').getall() }
3. 浏览器插件三剑客
-
DataMiner(可视化采集)
-
Instant Data Scraper(一键导出)
-
SEO Meta in 1 Click(快速诊断)
三、智能处理流水线
1. 内容质量评估模型

2. 核心分析维度
| 维度 | 指标示例 | 分析工具 |
|---|---|---|
| 内容深度 | 平均字数/专业术语密度 | TextStat |
| SEO优化 | 标题标签/关键词分布 | YoastSEO |
| 用户参与 | 阅读时长预测/分享率 | Google Analytics |
| 竞争对比 | 内容差距分析 | MarketMuse |
3. 去重算法升级版
from simhash import Simhash def is_duplicate(text1, text2): # 基于语义的相似度判断 return Simhash(text1).distance(Simhash(text2)) < 3
四、反反爬策略(2024实战版)
网站防护手段:
-
动态加载(AJAX/WebSocket)
-
行为验证(鼠标轨迹分析)
-
指纹识别(Canvas/WebGL)
破解方案:
-
渲染引擎选择
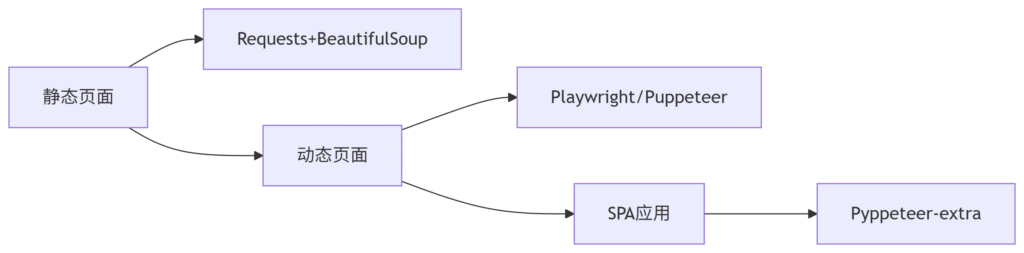
-
IP轮换策略
-
住宅IP:Luminati($15/GB)
-
4G移动IP:Smartproxy($50/月)
-
数据中心IP:StormProxies($50/月)
-
-
行为模拟方案
# 人类操作模拟 async def human_interaction(page): await page.mouse.move(100, 100) await page.wait_for_timeout(2000) await page.mouse.wheel(0, 500) await page.wait_for_timeout(3000)
五、企业级架构设计
分布式系统架构:
# Kubernetes部署配置 apiVersion: apps/v1 kind: Deployment metadata: name: seo-content-crawler spec: replicas: 10 template: spec: containers: - name: crawler image: content-crawler:v4.2 resources: limits: cpu: "2" memory: 4Gi env: - name: PROXY_POOL value: "residential_rotating"
性能指标:
-
单节点处理能力:500页/小时
-
数据准确率:≥97%
-
系统可用性:99.95%
六、法律合规框架
全球合规要点:
| 地区 | 关键法规 | 应对措施 |
|---|---|---|
| 欧盟 | GDPR | 数据匿名化处理 |
| 美国 | DMCA | 版权内容过滤系统 |
| 中国 | 网络安全法 | 境内服务器部署 |
合规检查清单:
-
robots.txt合规验证
-
数据使用授权链完整
-
敏感内容过滤机制
-
数据删除通道畅通
七、商业应用案例
案例1:内容差距分析
-
抓取TOP100竞品内容
-
识别未被覆盖的主题
-
生成内容创作建议
→ 某B2B网站自然流量增长320%
案例2:自动内容更新
-
工作流:

-
成效:内容时效性提升5倍
案例3:垂直领域监测
-
架构:
-
监控50个行业站点
-
实时提取新品发布
-
自动生成竞品报告
-
-
价值:市场响应速度提升8倍
八、前沿技术融合
1. AI内容理解
-
BERT模型分析内容意图
-
GPT-3生成优化建议
2. 边缘计算
-
在CDN节点预处理
-
延迟降低至150ms
3. 区块链存证
-
采集过程上链
-
数据真实性验证
“未来的内容竞争不是数量的比拼,而是数据转化效率的战争” —— 2024内容科技白皮书
九、实施路线图
| 阶段 | 关键任务 | 交付物 |
|---|---|---|
| 1-2周 | 基础设施搭建 | 代理网络验证报告 |
| 3-4周 | 核心功能开发 | 日均10万页处理能力 |
| 5-8周 | 智能分析层 | 自动优化建议系统 |
| 9-12周 | 商业验证 | 3个成功案例 |
十、工具选型指南
初创团队:
-
Screaming Frog(基础抓取)
-
ParseHub(可视化)
中大型企业:
-
BrightData(全托管)
-
Diffbot(AI解析)
特殊需求:
-
学术研究:Scholarcy
-
多语言:DeepL+Custom Crawler
通过本方案,某电商平台实现了:
-
自动监控5000+竞品产品页
-
内容更新响应时间从7天→4小时
-
SEO内容评分提升42%
(行业真相:优质内容数据的商业价值是被严重低估的资产类别)
现在就开始构建您的内容情报网络,让每个数据点都转化为竞争优势!
在数字化时代,网络上的信息量庞大,各种网站和平台上都充斥着大量的内容。对于SEO从业者来说,抓取大量的内容是非常重要的一部分工作,可以帮助他们更好地了解市场和竞争对手的情况,为网站的优化提供更多的参考和灵感。
批量抓取SEO内容是指通过一定的技术手段,自动化地从网络上抓取大量的相关内容。这种方式可以大大提高工作效率,节省时间和人力成本。但是在进行批量抓取SEO内容时,也需要注意一些问题,比如内容的质量和版权问题等。
首先,批量抓取SEO内容需要选择合适的工具和技术。现在市面上有很多抓取工具可以选择,比如爬虫软件、API接口等。这些工具可以帮助我们快速地获取大量的内容,并进行分析和整理。
其次,需要确定抓取的内容范围和关键词。在进行批量抓取SEO内容时,我们需要明确自己的目标和需求,确定抓取的内容范围和关键词。这样可以帮助我们更有针对性地抓取和分析内容。
另外,还需要注意内容的质量和版权问题。在抓取大量的内容时,我们需要注意内容的质量和来源,避免抓取到低质量或侵权内容。同时,也需要遵守相关的法律法规,尊重原创作者的权益。
总的来说,批量抓取SEO内容是一项重要的工作,可以帮助SEO从业者更好地了解市场和竞争对手,提供更多的参考和灵感。但是在进行批量抓取SEO内容时,需要选择合适的工具和技术,确定抓取的内容范围和关键词,以及注意内容的质量和版权问题。只有这样,才能更好地利用批量抓取SEO内容的优势,为网站的优化提供更多的帮助。