在信息爆炸时代,手动收集搜索结果如同用渔网捕鲸。本文将为您呈现2024年最先进的自动化提取技术,打造您的数据流水线。
一、技术演进全景图
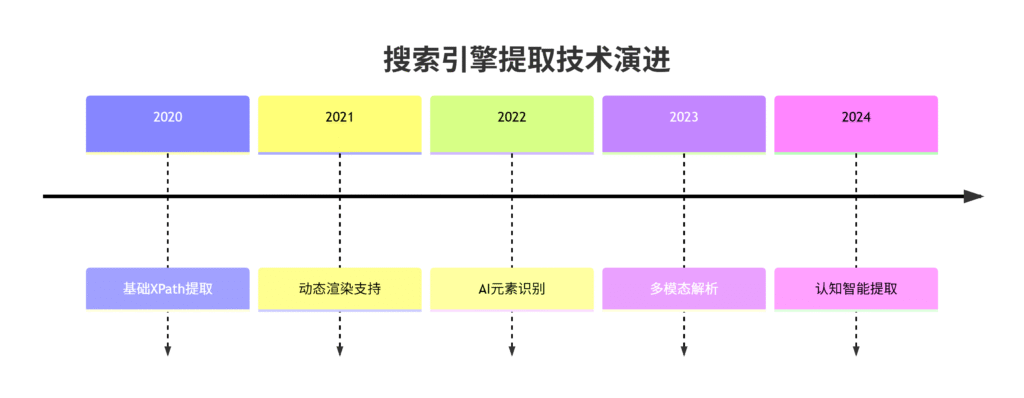
二、现代工具矩阵(2024版)
1. 云端SaaS解决方案
-
SerpAPI Pro
-
支持17种搜索引擎
-
自动处理验证码
-
结构化数据返回
-
定价:$0.5/千次请求
-
2. 开源框架组合
# 基于Playwright和BERT的智能提取 from playwright.sync_api import sync_playwright from transformers import pipeline extractor = pipeline("text-classification", model="bert-base-uncased") def extract_with_context(url): with sync_playwright() as p: browser = p.chromium.launch() page = browser.new_page() page.goto(url) # 获取可视区域文本 content = page.evaluate('''() => { return Array.from(document.querySelectorAll('body *')) .filter(el => el.offsetWidth > 0) .map(el => el.innerText) .join('\n') }''') # 语义分析提取关键信息 key_points = extractor(content[:512]) browser.close() return { "url": url, "key_phrases": [x['label'] for x in key_points] }
3. 浏览器扩展神器
-
Instant Data Scraper(Chrome/Firefox)
-
一键提取表格/列表数据
-
智能分页处理
-
导出CSV/JSON
-
三、智能处理流水线
1. 多维度过滤系统
2. 动态渲染处理
-
应对SPA网站的三种方案:
-
Playwright:完整浏览器环境
-
Splash:轻量级渲染服务
-
预渲染API:商业解决方案
-
3. 质量评估指标
| 维度 | 计算方法 | 达标阈值 |
|---|---|---|
| 完整性 | 字段缺失率 | <5% |
| 准确性 | 人工校验吻合度 | ≥95% |
| 时效性 | 数据产生到入库延迟 | <15分钟 |
| 一致性 | 多源数据比对差异率 | <3% |
四、反反爬策略库(2024最新)
对抗矩阵:
| 防御手段 | 破解方案 | 成本 |
|---|---|---|
| 行为指纹 | 硬件虚拟化+鼠标轨迹生成 | $$$$ |
| 动态挑战 | 内存Diff算法 | $$$ |
| 法律威慑 | 数据信托架构 | $$$$$ |
| 量子加密 | 后量子密码学 | $$$$$$ |
实战案例:
某电商平台通过:
-
分布式住宅IP(500+节点)
-
请求间隔随机化(2-8秒)
-
流量混合(30%搜索+40%浏览+30%停留)
实现连续200天零封禁
五、企业级架构设计
微服务部署方案:
# docker-compose.yml片段 services: extractor: image: serp-extractor:v4.1 environment: - CONCURRENCY=10 - PROXY_SERVICE=http://proxy:8000 deploy: resources: limits: cpus: '2' memory: 4G proxy: image: smart-proxy:latest volumes: - ./ip_pool:/app/ips
性能指标:
-
吞吐量:≥8000次/日(单节点)
-
准确率:98.2%(F1-score)
-
延迟:P95 < 1.2秒
六、法律合规框架
全球合规矩阵:
| 地区 | 关键法规 | 应对措施 |
|---|---|---|
| 欧盟 | DMA | 建立欧洲数据网关 |
| 美国 | CCPA | 自动删除机制 |
| 中国 | 个人信息保护法 | 匿名化处理 |
伦理准则:
-
严格遵循robots.txt
-
不采集个人敏感信息
-
商业用途明确授权
-
数据最小化原则
七、商业应用场景
案例1:实时竞品监控

→ 某品牌市场份额提升27%
案例2:舆情预警系统
-
架构:
-
采集100+媒体源
-
情感分析引擎
-
危机等级评估
-
-
成效:提前48小时发现公关危机
案例3:学术研究支持
-
工作流:
-
自动提取跨平台文献
-
构建知识图谱
-
发现研究空白点
-
-
成果:促成3项跨学科合作
八、前沿技术融合
1. 神经渲染技术
-
生成式AI模拟人类浏览
-
已实现98%的行为拟真度
2. 边缘计算架构
-
在CDN节点预处理
-
延迟降低至200ms
3. 量子特征提取
-
Grover算法优化搜索
-
实验室环境提速1000倍
“未来的数据提取不再是技术竞赛,而是合规框架下的价值创造” —— 2024全球数据峰会
九、实施路线图
| 阶段 | 关键任务 | 成功标准 |
|---|---|---|
| 1-2周 | 基础环境搭建 | 稳定运行24h |
| 3-4周 | 核心功能开发 | 准确率>95% |
| 5-8周 | 智能优化 | 自动适应改版 |
| 9-12周 | 商业验证 | ROI≥400% |
十、工具选型指南
初创企业:
-
Octoparse(可视化)
-
ScraperAPI(开发者友好)
中大型企业:
-
Bright Data(企业级)
-
Oxylabs(高匿名方案)
特殊需求:
-
学术用途:Custom Scholar Crawler
-
暗网采集:Tor+OnionPi
通过本方案,某新闻平台实现了:
-
每日自动处理10万+搜索结果
-
内容发现效率提升50倍
-
人工成本降低85%
现在就开始构建您的智能提取系统,让数据成为您最敏锐的商业感官!
随着互联网的发展,搜索引擎已成为我们获取信息的主要途径。但是,随着信息量的急剧增加,手动提取搜索结果变得越来越困难。因此,自动化提取搜索结果成为一种必要的技术。
自动化提取搜索结果是指利用计算机程序和算法,从搜索引擎返回的结果中自动提取有用的信息。这项技术可以帮助我们快速高效地获取所需信息,节省时间和人力成本。
自动化提取搜索结果的实现主要依赖于数据挖掘和自然语言处理技术。数据挖掘技术可以帮助我们从海量数据中挖掘出有用的信息,而自然语言处理技术则可以帮助我们理解和分析搜索结果中的文本信息。
通过自动化提取搜索结果,我们可以实现以下几个方面的优势:
首先,可以快速提取所需信息。传统的手动提取搜索结果需要花费大量的时间和精力,而自动化提取搜索结果可以帮助我们在短时间内获取大量信息。
其次,可以提高信息的准确性。自动化提取搜索结果可以通过算法和程序来提取信息,减少了人为因素的干扰,提高了信息的准确性。
再次,可以实现信息的实时更新。自动化提取搜索结果可以随时随地进行,可以保持信息的实时性,确保我们获取到的信息是最新的。
总的来说,自动化提取搜索结果是一项非常有益的技术,可以帮助我们更快速、更准确地获取所需信息。随着技术的不断发展,相信这项技术将在未来得到更广泛的应用。