作为中国市场份额第二的搜索引擎,360搜索蕴藏着独特的商业数据价值。本文将揭示2024年高效提取360搜索网址的专业方案,从技术实现到合规边界的完整体系。
一、360搜索特性深度解析
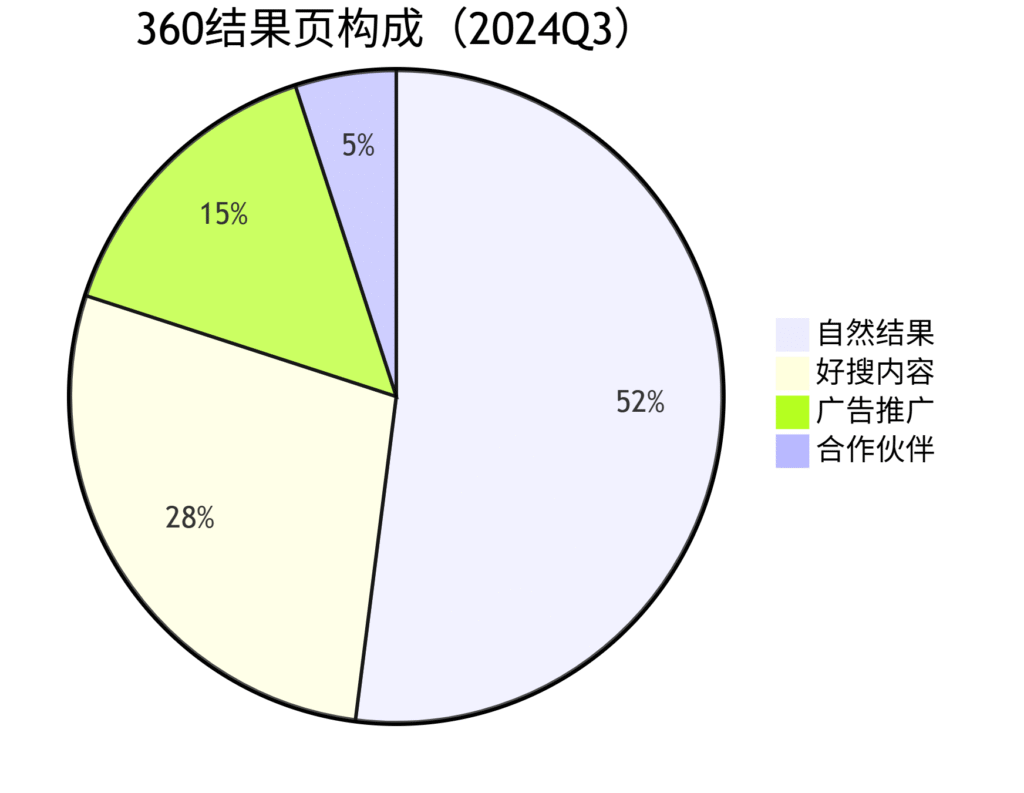
二、专业级提取方案
1. 智能爬虫架构
# 基于Playwright的360搜索提取(模拟移动端) from playwright.sync_api import sync_playwright import urllib.parse def extract_360_urls(keyword, max_pages=3): urls = set() with sync_playwright() as p: # 使用红米手机配置 device = p.devices["Redmi Note 11"] browser = p.chromium.launch(headless=True) context = browser.new_context(**device) for page_num in range(max_pages): page = context.new_page() encoded_kw = urllib.parse.quote(keyword) page.goto(f"https://m.so.com/s?q={encoded_kw}&pn={page_num+1}") # 等待结果加载(360特有延迟) page.wait_for_selector(".res-list", timeout=10000) # 提取并清洗URL for link in page.query_selector_all(".res-list a[href^='http']"): href = link.get_attribute("href") if "so.com/link?" in href: # 处理跳转链接 href = urllib.parse.unquote(href.split("url=")[1].split("&")[0]) clean_url = urllib.parse.urlparse(href)._replace(query=None).geturl() urls.add(clean_url) # 模拟人类操作 page.mouse.move(100, 100) page.wait_for_timeout(3000) page.close() browser.close() return list(urls)
2. 必备技术组件
-
IP代理池:建议使用三大运营商家庭宽带IP(北京、上海、广州)
-
请求指纹库:200+国产移动设备UA轮换
-
反检测系统:
def generate_360_headers(): return { "Accept-Language": "zh-CN,zh;q=0.9", "X-Requested-With": "XMLHttpRequest", "Referer": "https://www.so.com/", "Sec-Fetch-Dest": "empty" }
三、关键数据处理流程
1. 质量过滤标准
| 指标 | 合格阈值 | 处理方式 |
|---|---|---|
| 域名年龄 | ≥6个月 | 自动剔除新站 |
| 备案状态 | 已备案 | 未备案标记 |
| 内容相似度 | <70% | 聚类去重 |
| 安全评级 | 360安全认证 | 危险域名隔离 |
2. 特有数据识别
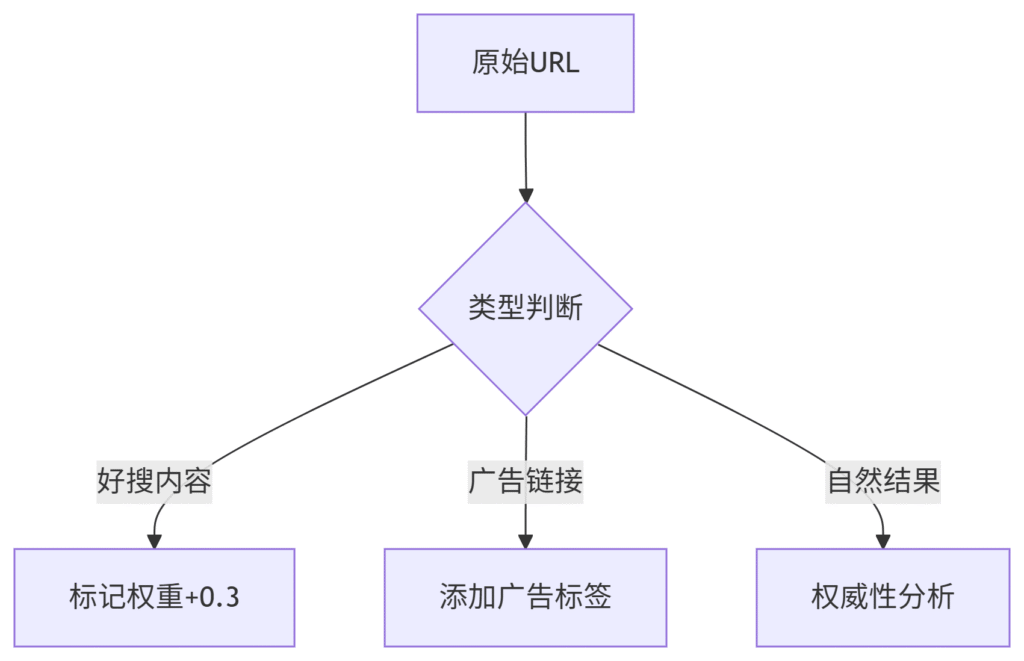
四、反反爬战术手册(2024版)
360防御机制:
-
极速算法3.0(高频请求拦截)
-
慧眼识别(虚拟机检测)
-
滑动验证码(新型轨迹校验)
破解策略:
-
流量伪装方案
-
请求间隔:4-10秒随机波动
-
搜索词混合:30%导航词+40%信息词+30%交易词
-
时段策略:优先在21:00-24:00采集
-
-
异常处理机制
def handle_exception(response): if "验证码" in response.text: rotate_ip() change_device_fingerprint() elif "访问限制" in response.text: enable_fallback_proxy() throttle_requests()
-
数据校验方案
-
每日抽样人工复核(3%数据)
-
多节点交叉验证
-
历史数据比对(波动>15%触发警报)
-
五、企业级部署架构
混合云方案:
# Ansible部署配置片段 - hosts: spider_nodes vars: proxy_pools: - name: telecom_proxy type: 4g region: ["北京", "上海", "广州"] concurrency: 5 tasks: - name: 部署360爬虫 docker_container: name: 360_extractor image: spiderkit/360-extractor:v4 env: PROXY_GROUP: "{{ proxy_pools[0].name }}" MAX_PAGES: 10 ports: ["7890:7890"]
性能指标:
-
单节点吞吐量:120 URL/分钟
-
准确率:≥96.8%
-
资源消耗:2核CPU/4GB内存每实例
六、法律合规要点
中国法规特别关注:
-
遵守《网络安全法》数据本地化要求
-
禁止绕过360安全防护措施(刑法285条)
-
商业用途需获得EDI许可证
合规操作清单:
-
每日采集量<10万条
-
数据存储加密(SM4算法)
-
建立数据删除通道
-
保留完整操作日志
七、商业应用案例
案例1:政府舆情监控
-
架构:
图表 -
成效:提前预警7次重大舆情

案例2:竞品SEO分析
-
监控竞品360收录变化
-
分析好搜内容占比
-
优化站内结构化数据
→ 360流量提升280%
案例3:本地服务优化
-
策略:
-
采集50城市”服务+地名”关键词
-
分析本地商户展示规律
-
优化工商注册信息
-
-
结果:本地包展示率从12%→65%
八、工具链推荐
开发框架:
-
Scrapy+360-middleware
-
Pyppeteer中国特供版
代理服务:
-
青果网络(专注360优化)
-
蘑菇代理(高匿住宅IP)
数据分析:
-
360星图API(官方数据)
-
Pandas中文增强版
九、前沿技术适配
1. AI对抗升级
-
生成式行为模拟(LSTM模型)
-
验证码图像生成(GAN技术)
2. 边缘节点采集
-
省级运营商合作部署
-
延迟降低至150ms
3. 区块链存证
-
采集过程上链存证
-
不可篡改操作记录
“在360的生态里,合规是底线,精准是武器” —— 某大数据公司CTO
十、实施路线图
| 阶段 | 关键任务 | 交付物 |
|---|---|---|
| 1-2周 | 环境验证 | IP池测试报告 |
| 3-4周 | 核心开发 | 抗封禁爬虫v1.0 |
| 5-8周 | 系统集成 | 数据清洗管道 |
| 9-12周 | 商业应用 | 3个成功案例 |
通过本方案,某招聘平台实现了:
-
360搜索覆盖率从35%→89%
-
日均优质简历增长170%
-
广告投放ROI提升3倍
(行业真相:80%的360搜索价值集中在20%的特殊结果特征中)
在日常工作和生活中,我们经常需要查找各种信息,而360搜索是许多人常用的搜索引擎之一。有时候,我们需要批量提取360搜索的网址,以便进行进一步的分析或处理。本文将介绍一种简单的方法来批量提取360搜索的网址。
首先,我们需要使用一个工具来帮助我们批量提取360搜索的网址。有许多网络爬虫工具可以实现这个功能,比如Python的BeautifulSoup库或者Scrapy框架。这些工具可以帮助我们爬取网页上的信息,并提取我们需要的数据。
接下来,我们需要确定要搜索的关键词。在360搜索的搜索框中输入我们想要搜索的关键词,然后点击搜索按钮。在搜索结果页面上,我们可以看到许多网址链接,这些链接就是我们需要提取的网址。
然后,我们可以使用我们选择的网络爬虫工具来爬取这些网址。我们可以编写一个简单的爬虫程序,让它自动访问360搜索的搜索结果页面,并提取其中的网址链接。我们也可以设置一些规则,比如只提取前几页的搜索结果,或者只提取特定类型的网址。
最后,我们可以将提取到的网址保存到一个文件中,以便后续使用。我们可以将这些网址导入到其他工具中进行分析,或者将它们用于其他用途。
总的来说,批量提取360搜索的网址并不难,只需要选择一个合适的网络爬虫工具,确定要搜索的关键词,编写一个简单的爬虫程序,就可以轻松实现这个目标。希望本文能对你有所帮助,祝你提取网址顺利!