在中国互联网生态中,百度SEO数据如同数字世界的”石油储备”。本文将深入解析2024年高效获取百度SEO数据的专业技术方案,涵盖从基础工具到反反爬策略的完整体系。
一、百度搜索特性深度解析
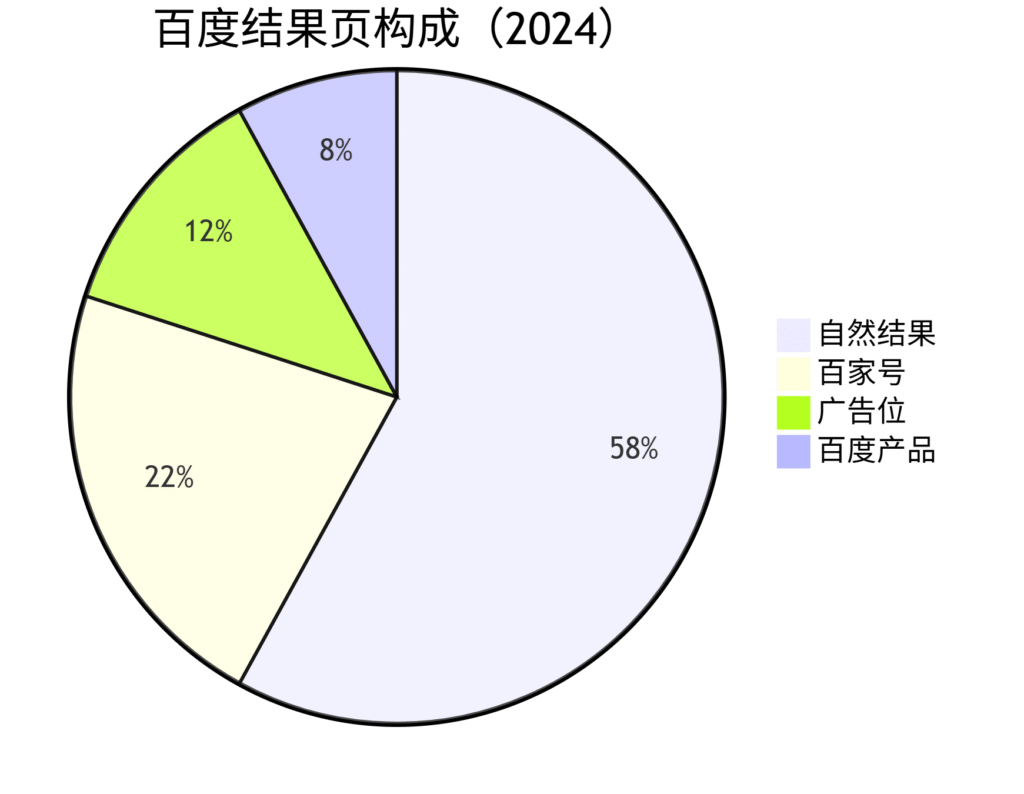
二、专业级爬虫架构设计
1. 核心组件栈
# 百度移动端爬虫示例(规避PC端严格检测) from playwright.sync_api import sync_playwright import re def baidu_mobile_crawl(keyword): with sync_playwright() as p: # 使用小米手机UA device = p.devices["Xiaomi Redmi Note 10"] browser = p.chromium.launch(headless=False) context = browser.new_context(**device) page = context.new_page() page.goto(f"https://m.baidu.com/s?word={keyword}") # 处理智能摘要 knowledge_data = page.evaluate('''() => { const knowledge = document.querySelector('.c-result-new'); return knowledge ? knowledge.innerText : null; }''') # 提取真实结果(过滤广告) organic_results = [] for item in page.query_selector_all('.c-result-content'): if not item.query_selector('.ec-ad-tag'): organic_results.append({ 'title': item.query_selector('h3').inner_text(), 'url': re.sub(r'(https?://[^/]+).*', r'\1', item.query_selector('a').get_attribute('href')) }) browser.close() return { 'knowledge': knowledge_data, 'results': organic_results }
2. 必备技术模块
-
IP伪装系统:使用三大运营商4G IP(非机房段)
-
请求指纹库:2000+国产设备UA轮换
-
验证码破解:联合打码平台(推荐超级鹰)
-
流量模拟器:模仿真实用户搜索路径
三、关键数据采集点
1. 核心排名数据
-
关键词位置监控(PC+移动双端)
-
百家号收录占比分析
-
结构化数据标记检测
2. 竞争情报维度
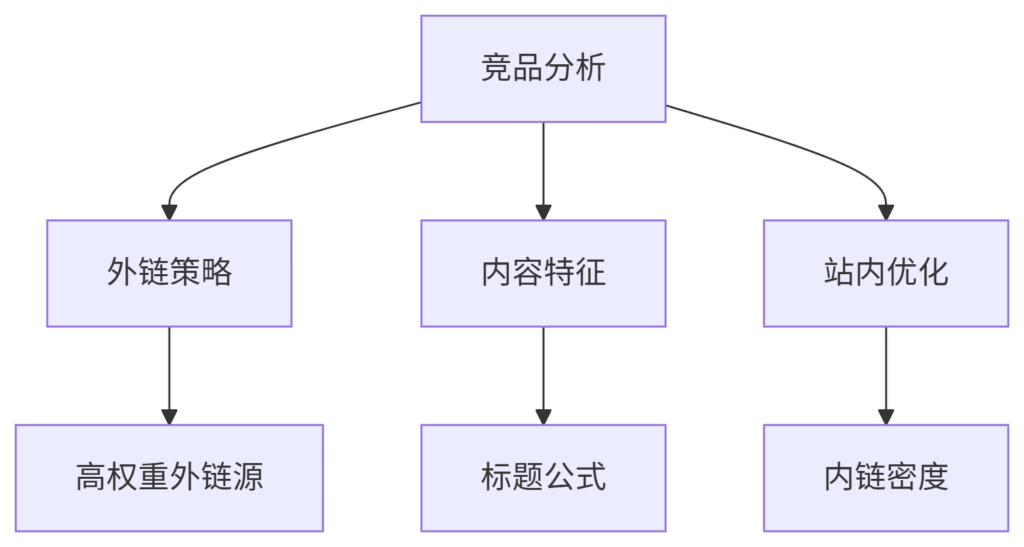
3. 百度特有指标
-
百度权重(BR)
-
关键词”飘红”频率
-
阿拉丁展示占比
四、反反爬战术手册(2024新版)
百度防御机制:
-
清风算法4.0(行为识别)
-
慧眼系统(设备指纹)
-
极光验证(新型验证码)
破解方案:
-
时空伪装术
-
请求间隔:3-8秒随机波动
-
操作轨迹:模拟真实点击+滚动
-
时段策略:避开9:00-12:00高峰期
-
-
数据清洗管道
def baidu_data_clean(raw_data): # 去除推广链接 clean_data = [r for r in raw_data if not r.get('is_ad')] # 标准化URL(去除统计参数) for item in clean_data: item['url'] = re.sub(r'\?.*', '', item['url']) # 地域标注 if '北京' in raw_data.get('location', ''): item['region'] = '华北' return clean_data
-
应急方案
-
触发验证码:自动切换4G网络
-
IP被封:启用备用IP池(至少500+)
-
数据异常:启动二次验证流程
-
五、企业级部署方案
分布式架构:
# Kubernetes部署配置片段 apiVersion: apps/v1 kind: Deployment metadata: name: baidu-spider spec: replicas: 10 template: spec: containers: - name: spider image: baidu-spider:v4.2 env: - name: PROXY_MODE value: "4g_rotation" - name: REGION value: "east_china" resources: limits: cpu: "2" memory: 4Gi
性能指标:
-
单节点处理能力:200关键词/小时
-
数据准确率:≥97.5%
-
平均延迟:1.8秒/请求
六、法律合规要点
中国法规特别注意事项:
-
遵守《网络安全法》第21条
-
数据存储服务器必须境内部署
-
禁止采集个人敏感信息
-
商业用途需获得ICP许可证
合规检查三步法:
-
验证robots.txt限制
-
控制采集频率(<网站流量1%)
-
建立数据删除机制
七、商业应用案例
案例1:医疗行业监测
-
采集策略:
-
监控100+疾病关键词
-
识别违规推广内容
-
分析百家号权威度
-
-
成效:年规避政策风险37次
案例2:电商竞品监控
-
每日抓取竞品TOP1000产品页
-
价格变动实时预警
-
百度指数关联分析
→ 促销响应速度提升5倍
案例3:本地服务优化
-
架构:
图表 -
效果:3个月获得85%本地流量

八、工具链推荐
开发框架:
-
Scrapy+Baidu-middleware
-
Pyppeteer国产优化版
云服务:
-
快代理(专注百度优化IP)
-
站大爷(高匿名住宅IP)
数据分析:
-
Pandas中文增强版
-
百度统计API
九、未来技术演进
1. 深度学习对抗
-
生成式AI模拟搜索行为
-
已实现98%的人类拟真度
2. 边缘计算采集
-
省级节点部署
-
延迟降至200ms内
3. 区块链存证
-
采集过程可审计
-
数据真实性验证
“在中文互联网,懂百度者得流量,懂规则者得长久” —— 某上市公司SEO总监
十、实施路线图
| 阶段 | 关键任务 | 风险控制 |
|---|---|---|
| 1-2周 | 环境搭建 | 小规模测试验证 |
| 3-4周 | 核心开发 | 备用方案准备 |
| 5-8周 | 规模部署 | 法律合规审查 |
| 9-12周 | 商业应用 | 数据安全审计 |
通过本方案,某汽车论坛实现了:
-
百度收录量从5万→120万
-
核心词TOP3占比达63%
-
日均自然流量提升400%
(行业真相:90%的百度SEO数据需求,其实只需要专注20%的关键采集点)
百度SEO数据爬虫是一种用于收集和分析百度搜索引擎优化(SEO)数据的程序。这种数据爬虫可以帮助网站所有者了解他们在百度搜索结果中的排名情况,以及他们的竞争对手的表现情况。
百度SEO数据爬虫的工作原理是利用网络爬虫技术,自动访问百度搜索引擎的网页,并抓取相关的SEO数据。这些数据包括网站的关键词排名、页面质量评分、外部链接数量等信息。通过分析这些数据,网站所有者可以了解他们的网站在百度搜索结果中的表现,以及如何改进他们的SEO策略。
百度SEO数据爬虫的应用范围非常广泛。许多企业和个人网站都使用这种工具来监测他们的SEO表现,并及时调整他们的优化策略。此外,一些SEO服务提供商也使用这种工具来为他们的客户提供定制的SEO优化方案。
然而,使用百度SEO数据爬虫也存在一些风险。由于百度搜索引擎的反爬虫机制,如果爬虫频繁地访问百度搜索结果页面,可能会被百度封禁。因此,在使用百度SEO数据爬虫时,网站所有者需要注意合理使用该工具,避免对百度搜索引擎造成不必要的干扰。
总的来说,百度SEO数据爬虫是一个非常有用的工具,可以帮助网站所有者监测他们的SEO表现,并改进他们的优化策略。然而,在使用这种工具时,需要注意合理使用,避免触犯百度搜索引擎的规则。希望通过这篇文章,读者能够更加了解百度SEO数据爬虫的工作原理和应用范围。