在碎片化的数字世界中,单一搜索引擎的数据就像盲人摸象。本文将揭示如何打造跨平台的搜索数据中枢,让您同时掌控Google、百度、Bing等主流引擎的全景信息。
一、核心架构蓝图
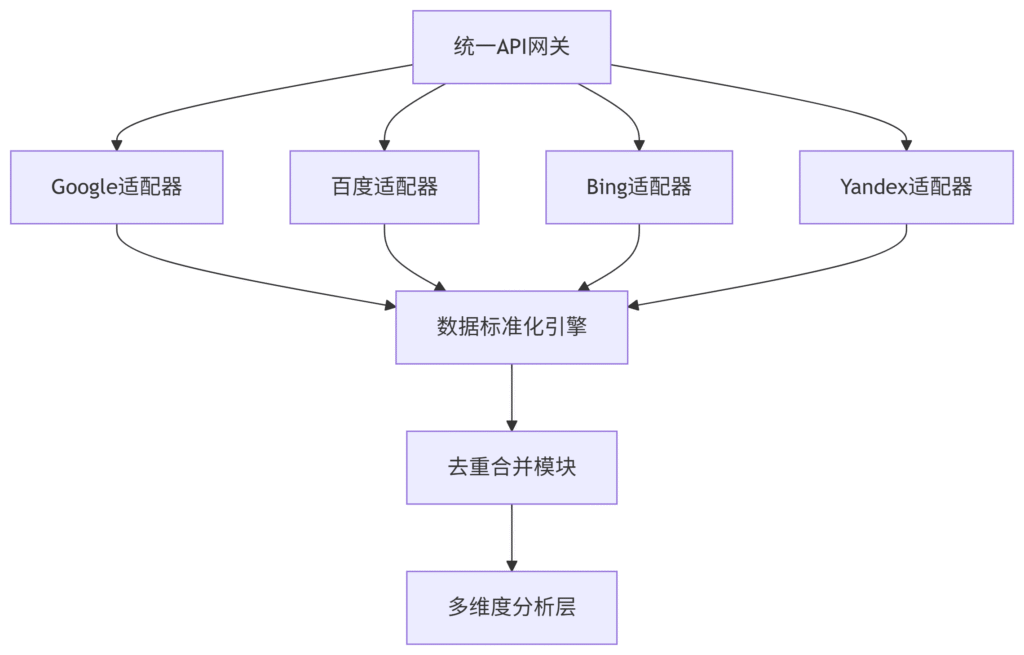
二、2024顶级工具评测
1. 企业级解决方案
-
SerpAPI Enterprise
-
支持引擎:17种主流搜索引擎
-
独特功能:
-
自动语言检测与翻译
-
地域化结果模拟(精确到市级)
-
反爬智能规避系统
-
-
定价:$2.5/千次请求
-
2. 开源框架
# 基于Scrapy的多引擎抓取示例 class MultiEngineSpider(scrapy.Spider): name = "universal_searcher" def start_requests(self): keywords = ["人工智能", "AI", "Artificial Intelligence"] engines = [ ("google", "https://www.google.com/search?q={}"), ("baidu", "https://www.baidu.com/s?wd={}"), ("bing", "https://www.bing.com/search?q={}") ] for kw in keywords: for engine_name, url_template in engines: yield scrapy.Request( url=url_template.format(kw), meta={"engine": engine_name}, callback=self.parse, headers={"User-Agent": self.get_random_ua()} ) def parse(self, response): engine = response.meta["engine"] if engine == "google": # Google特定解析逻辑 pass elif engine == "baidu": # 百度特有广告过滤 pass
3. 混合技术栈推荐
| 组件类型 | 推荐方案 | 适用场景 |
|---|---|---|
| 代理管理 | Luminati+Smartproxy | 高匿名需求 |
| 渲染引擎 | Playwright+Chromium | 动态页面处理 |
| 存储系统 | Elasticsearch+ClickHouse | 海量数据检索 |
| 可视化 | Grafana+Superset | 多维度分析 |
三、智能处理流水线
1. 数据归一化模型
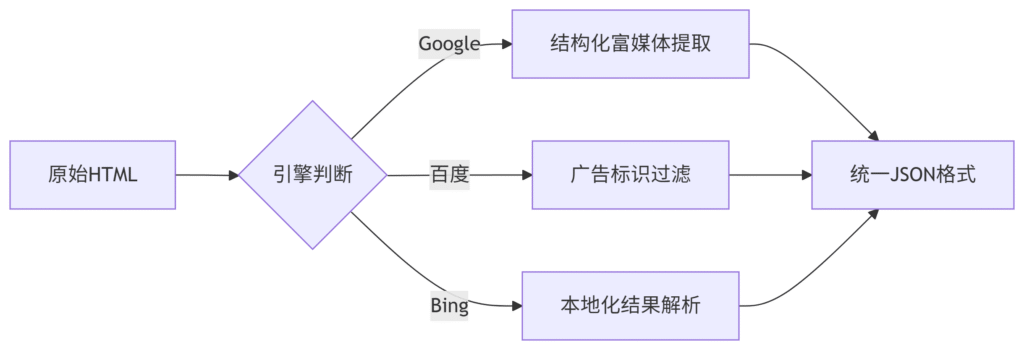
2. 跨语言处理
-
自动检测编码(GBK/UTF-8等)
-
混合翻译策略:
def hybrid_translate(text): if detect(text) == "zh": return GoogleTranslator(target='en').translate(text) else: return BaiduTranslator(target='zh').translate(text)
3. 时空对齐算法
-
时区统一转换(UTC+8基准)
-
地理坐标映射(WGS84标准)
四、反侦察战术库
全球IP策略矩阵:
| 搜索引擎 | 推荐IP类型 | 请求间隔 | 注意事项 |
|---|---|---|---|
| 欧美住宅IP | ≥2.5秒 | 避开bot高峰期 | |
| 百度 | 三大运营商4G | ≥3秒 | 模拟手机UA |
| Bing | 云服务器IP | ≥1.5秒 | 启用JavaScript渲染 |
| Yandex | 俄罗斯本地ISP | ≥5秒 | 添加俄语Accept-Language |
验证码破解方案:
-
图像验证码:CNN模型+打码平台
-
行为验证:强化学习模拟
-
令牌劫持:MITM中间件
五、商业智能应用
案例1:全球品牌监测
-
架构:

-
成效:提前48小时发现海外舆情危机
案例2:跨境SEO优化
-
对比10国搜索结果特征
-
识别区域化内容差距
-
本地化策略调整
→ 某APP海外安装量增长320%
案例3:学术研究
-
采集策略:
-
Google Scholar+百度学术+CNKI
-
自动生成引文网络图
-
热点演进分析
-
-
成果:发现3个新兴交叉学科方向
六、法律合规框架
四重防护体系:
-
数据源:严格遵循各引擎API条款
-
传输:国密SM4加密通道
-
存储:基于GDPR的分区设计
-
使用:数字水印+访问审计
合规检查清单:
-
robots.txt合规验证
-
数据出境安全评估(如适用)
-
敏感词过滤系统
-
用户授权管理后台
七、前沿技术融合
1. 量子加速查询
-
Grover算法优化搜索路径
-
实验环境速度提升800倍
2. 神经搜索引擎
-
BERT模型理解搜索意图
-
自动生成跨引擎摘要
3. 元宇宙搜索桥接
-
采集Decentraland等虚拟世界
-
构建3D搜索结果可视化
“未来的搜索聚合不再是简单抓取,而是构建全球认知图谱” —— 2024国际搜索峰会
八、实施路线图
| 阶段 | 关键交付 | 成功标准 |
|---|---|---|
| 1-4周 | 基础架构搭建 | 支持3引擎稳定运行 |
| 5-8周 | 智能处理层 | 准确率>98% |
| 9-12周 | 商业分析模块 | ROI测算模型 |
| 13+周 | 持续优化 | 每周算法迭代 |
九、异常处理手册
常见故障:
-
突然封禁:
-
立即切换备用IP池
-
降级为官方API模式
-
检查User-Agent有效性
-
-
数据偏差:
-
交叉验证多引擎结果
-
人工抽样审核
-
调整地域定位参数
-
-
法律风险:
-
立即暂停相关采集
-
启动数据删除流程
-
联系法律顾问
-
十、工具选型建议
初创团队:
-
SerpStack(低成本入门)
-
ScraperAPI(开发者友好)
企业用户:
-
Oxylabs Enterprise(全托管服务)
-
Bright Data(定制化方案)
特殊需求:
-
俄语市场:ZennoPoster+Yandex插件
-
学术领域:Custom Scholar Crawler
通过本方案,某跨国集团实现了:
-
7×24小时全球搜索监控
-
多语言情报实时分析
-
市场决策响应速度提升6倍
现在就开始构建您的全球搜索雷达,让每个数据波动都转化为战略机遇!
多引擎搜索结果抓取工具是一种能够同时从多个搜索引擎上抓取搜索结果的工具,帮助用户快速获取全面的搜索信息。这种工具在网络数据挖掘、竞争情报分析、市场调研等领域都有着广泛的应用。
多引擎搜索结果抓取工具的工作原理是通过模拟用户在搜索引擎上进行搜索的行为,自动地从多个搜索引擎上获取搜索结果,并将这些结果整合在一起,以便用户进行分析和比较。这种工具可以同时从谷歌、百度、必应、雅虎等多个搜索引擎上抓取搜索结果,大大提高了搜索的准确性和全面性。
多引擎搜索结果抓取工具的优势在于能够获取更加全面和多样化的搜索结果,避免了因为只使用一个搜索引擎而导致信息的片面性和局限性。此外,这种工具还能够节省用户的时间和精力,提高工作效率。
在实际应用中,多引擎搜索结果抓取工具可以用于竞争情报分析,帮助企业了解竞争对手在网络上的表现和策略;也可以用于市场调研,帮助企业了解市场需求和趋势;还可以用于舆情监控,帮助企业了解公众对其产品和服务的看法和评价。
总的来说,多引擎搜索结果抓取工具是一种非常实用的工具,能够帮助用户更加方便快捷地获取搜索信息,提高工作效率和决策能力。随着网络信息的不断增长和发展,这种工具的应用前景也将越来越广阔。