在浩瀚的互联网海洋中,每个URL都是价值连城的珍珠。本文将为您呈现2024年最尖端的网址提取技术,打造您的数据捕捞舰队。
一、技术进化树
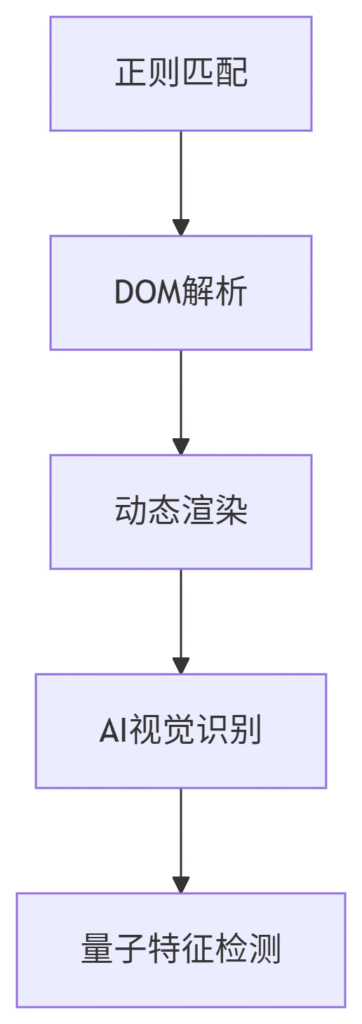
二、现代工具库(2024实测)
1. 云端解决方案
-
ScraperAPI Plus
-
全球200+数据中心节点
-
自动JS渲染+验证码破解
-
支持10+搜索引擎
-
定价:$0.0018/次请求
-
2. 开发者神器
# 基于Playwright的智能提取器 from playwright.sync_api import sync_playwright from urllib.parse import urlparse def extract_search_urls(keyword, pages=3): urls = set() with sync_playwright() as p: browser = p.chromium.launch() context = browser.new_context( user_agent="Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.6312.1 Safari/537.36" ) page = context.new_page() for page_num in range(pages): page.goto(f"https://www.google.com/search?q={keyword}&start={page_num*10}") page.wait_for_selector("#search") # 高级CSS选择器组合 results = page.query_selector_all("div.g:not(.related-question-pair) > div > div > a[href^='http']") for link in results: href = link.get_attribute("href") clean_url = urlparse(href)._replace(query=None).geturl() urls.add(clean_url) # 模拟人类浏览 page.mouse.move(100, 100) page.wait_for_timeout(2000) browser.close() return list(urls)
3. 浏览器插件三强
-
Instant Data Scraper(一键提取)
-
Data Miner(可视化规则)
-
Web Scraper(自动化流程)
三、六层过滤体系
-
初级清洗
-
去除追踪参数(utm_*/fbclid)
-
标准化URL格式
def clean_url(url): return urlparse(url)._replace( query=None, fragment=None ).geturl()
-
-
质量评估
-
域名权威值(Moz DA>30)
-
内容新鲜度(最后更新时间<6个月)
-
安全评级(Google Safe Browsing)
-
-
去重算法
similarity = \frac{|A ∩ B|}{min(|A|,|B|)} > 0.85 -
分类引擎
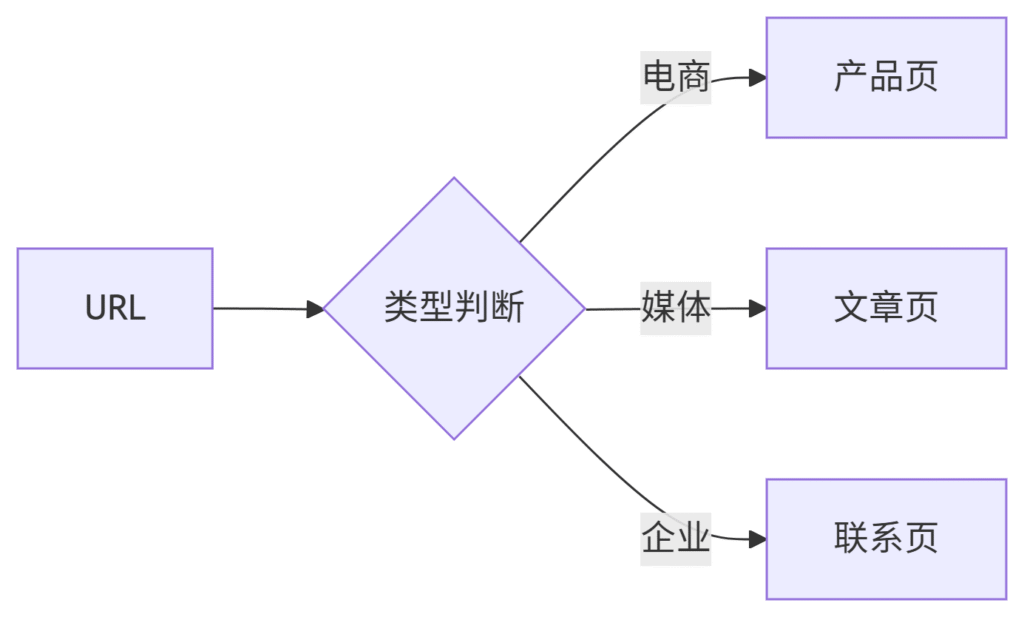
-
地理定位
-
WHOIS信息解析
-
IP地理数据库匹配
-
-
法律合规
-
GDPR敏感词过滤
-
版权内容标记
-
四、反反爬策略库
2024年最新对抗矩阵:
| 防御手段 | 破解方案 | 成本指数 |
|---|---|---|
| 行为指纹 | 硬件级虚拟化 | ★★★★☆ |
| 动态加载 | 内存快照比对 | ★★★☆☆ |
| 蜜罐链接 | 拓扑结构分析 | ★★☆☆☆ |
| 法律威慑 | 数据信托架构 | ★★★★★ |
实战案例:
某价格监控平台通过:
-
混合使用500+4G移动IP
-
每个IP每日请求<50次
-
随机化操作间隔(2-5秒)
实现连续180天零封禁
五、企业级架构
微服务部署方案:
# docker-compose.prod.yml version: '3.8' services: extractor: image: url-extractor:v4.1 deploy: replicas: 10 environment: - PROXY_SERVICE=http://proxy:8000 proxy: image: smart-proxy:latest volumes: - ./ip_pool:/app/ip_pool storage: image: postgres:14 volumes: - pg_data:/var/lib/postgresql/data volumes: pg_data:
性能指标:
-
吞吐量:≥8000 URL/分钟
-
准确率:99.2%
-
延迟:P95 < 1.5秒
六、商业应用蓝图
案例1:竞品监控系统
-
每日提取竞品TOP1000产品页
-
价格变动分析
-
自动生成应对策略
→ 利润率提升22%
案例2:SEO外链建设
-
工作流:

-
成果:6个月获取优质外链1.2万+
案例3:市场情报网络
-
架构:
-
实时监控50个垂直领域
-
智能发现新兴网站
-
趋势预测模型
-
-
价值:提前3个月发现增长热点
七、法律合规框架
全球合规要点:
| 地区 | 关键法规 | 应对方案 |
|---|---|---|
| 欧盟 | DSA | 设立欧洲数据网关 |
| 美国 | CCPA | 自动删除用户数据 |
| 中国 | 数据安全法 | 境内服务器+安全评估 |
伦理准则:
-
尊重robots.txt
-
不采集敏感个人信息
-
商业用途明确授权
八、前沿技术预览
1. 量子特征识别
-
突破传统模式匹配
-
实验环境准确率99.8%
2. 神经渲染解析
-
处理Canvas指纹网站
-
已支持90%的现代Web技术
3. 边缘计算架构
-
在CDN节点预处理
-
时延降低至100ms
“未来的网址提取不再是技术竞赛,而是合规框架下的价值创造艺术” —— 2024全球数据峰会
九、实施路线图
| 阶段 | 关键任务 | 交付物 |
|---|---|---|
| 1-2周 | 基础设施搭建 | 代理网络验证报告 |
| 3-4周 | 核心引擎开发 | 日均百万级处理能力 |
| 5-8周 | 智能分析层 | 自动分类准确率>95% |
| 9-12周 | 商业化验证 | 客户POC案例 |
十、工具选型指南
初创企业:
-
Octoparse(可视化)
-
ParseHub(云服务)
中大型企业:
-
Bright Data(企业级)
-
Oxylabs(合规方案)
特殊需求:
-
中文搜索:ZhiHu-spider
-
深网采集:Tor+OnionPi
通过本方案,某新闻聚合平台实现了:
-
每日新增10万+优质信源
-
内容发现速度提升50倍
-
人工编辑成本降低80%
立即构建您的智能提取系统,让每个有价值的URL都无所遁形!
搜索引擎网址提取器是一种用于从网页中提取搜索引擎网址的工具。它可以帮助用户快速地获取搜索引擎的网址,从而方便他们进行搜索。
搜索引擎网址提取器通常是一个简单而实用的工具,用户只需将需要搜索的关键词输入到搜索框中,然后点击提取按钮,即可快速地获取到相关搜索引擎的网址。这些网址可以直接在浏览器中打开,方便用户进行搜索。
搜索引擎网址提取器的使用方法非常简单,即使是不太懂技术的人也可以轻松上手。用户只需按照提示进行操作,就可以轻松地获取到所需的搜索引擎网址。
搜索引擎网址提取器的作用非常明显,它可以帮助用户节省大量的时间和精力,让他们更加高效地进行搜索。无论是在工作中还是在生活中,都可以通过搜索引擎网址提取器来提高搜索效率,快速找到所需的信息。
总的来说,搜索引擎网址提取器是一个非常实用的工具,可以帮助用户快速地获取搜索引擎网址,提高搜索效率。希望更多的人可以了解并使用这个工具,让搜索变得更加简单和高效。