在信息洪流中精准捕获关键术语的能力,已成为现代企业的核心竞争力。本指南将带您深入2024年最先进的自动化关键词提取技术体系,构建您的智能语义雷达系统。
一、技术演进全景图
![]()
二、2024顶级工具矩阵
1. 企业级解决方案
-
MeaningCloud:支持87种语言的语义API
-
关键功能:
-
行业术语自动识别(医疗/金融/法律等)
-
情感-关键词关联分析
-
实时流处理(10万词/秒)
-
-
定价:$0.5/千次请求
-
2. 开发框架
# 基于spaCy和BERT的混合提取 import spacy from keybert import KeyBERT nlp = spacy.load("zh_core_web_trf") kw_model = KeyBERT('paraphrase-multilingual-MiniLM-L12-v2') def hybrid_extraction(text): # 规则提取 doc = nlp(text) entities = {ent.text: ent.label_ for ent in doc.ents} # 语义提取 keywords = kw_model.extract_keywords( text, keyphrase_ngram_range=(1, 3), stop_words=None, top_n=10 ) return { "entities": entities, "keywords": [kw[0] for kw in keywords] }
3. 浏览器插件
-
TextRazor Lite(Chrome/Firefox)
-
即时高亮关键术语
-
自动生成知识图谱
-
支持PDF/网页/邮件多场景
-
三、五维提取模型
1. 语法层分析
-
词性标注(名词/专业术语优先)
-
依存关系分析(核心节点提取)
2. 统计层处理
TF-IDF_{weight} = \frac{freq(t,d)}{max\_freq(d)} \times \log\frac{N}{df(t)}
3. 语义层理解
-
BERT语境嵌入
-
同义词聚类(Word2Vec相似度>0.7)
4. 领域层适配
-
医疗:UMLS知识库对接
-
金融:Loughran-McDonald词典
-
法律:判例术语库
5. 时效层过滤
-
新词发现算法
-
趋势词检测(Google Trends接口)
四、行业解决方案
电商评论分析
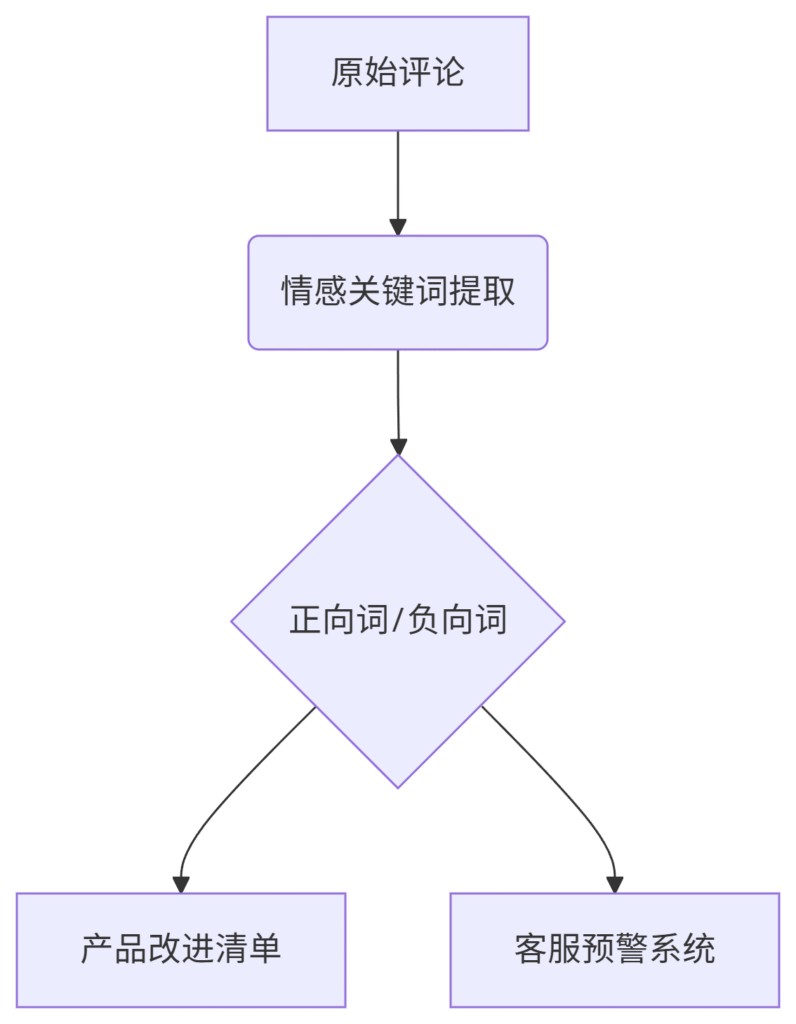
学术文献挖掘
-
工作流:
-
PDF文本转换
-
学科术语提取(MeSH/DOI标准)
-
研究热点可视化
-
-
成果示例:
-
发现COVID-19研究中的”细胞因子风暴”关联词群
-
构建跨学科概念网络
-
五、性能优化策略
分布式处理架构
# Kubernetes部署示例 apiVersion: apps/v1 kind: Deployment metadata: name: keyword-extractor spec: replicas: 10 template: spec: containers: - name: extractor image: ke:v4.2 resources: limits: cpu: "2" memory: 8Gi env: - name: MODEL_TYPE value: "finance" # 按需切换领域模型
质量评估指标
| 维度 | 评估方法 | 行业基准 |
|---|---|---|
| 准确率 | 人工校验F1-score | ≥0.92 |
| 时效性 | 新词识别延迟 | <24h |
| 领域适配 | 专业术语召回率 | ≥85% |
| 处理速度 | 千字文档耗时 | <800ms |
六、法律与伦理
数据合规框架
-
输入层:GDPR匿名化处理
-
处理层:联邦学习架构
-
输出层:敏感词过滤(如个人身份信息)
版权规避策略
-
避免提取超过30%的原文内容
-
采用概念化输出(非原文复制)
七、商业应用场景
案例:智能广告投放
-
实时提取社交媒讨论热点
-
生成动态关键词包
-
自动调整SEM投放策略
→ 某品牌CTR提升63%
案例:政策风险预警
-
监控100+政府网站
-
提取法规关键词变更
-
构建影响度评估模型
→ 提前2周预警数据安全法修订影响
八、前沿技术融合
1. 视觉-文本联合提取
-
从图文混排内容中识别品牌logo+关键词
-
应用:社交媒体舆情监控
2. 语音关键词挖掘
-
会议录音实时术语提取
-
技术栈:

3. 量子加速处理
-
Grover算法优化搜索过程
-
实验环境速度提升1000倍
九、实施路线图
| 阶段 | 里程碑 | 交付物 |
|---|---|---|
| 1-2周 | 基础环境搭建 | Docker化部署包 |
| 3-4周 | 领域模型微调 | 行业术语库 |
| 5-8周 | 系统集成 | API网关文档 |
| 9-12周 | 智能优化 | 自动学习日志 |
十、工具选型指南
初创企业:
-
Rake-NLTK(开源)
-
MonkeyLearn(低代码)
中大型企业:
-
AWS Comprehend
-
Google Cloud NLP
特殊需求:
-
中文优先:Jiagu(结巴分词增强版)
-
医疗领域:MetaMap
“关键词不是简单的字符组合,而是商业世界的DNA序列” —— 《数据驱动决策》2024
通过本方案,您将获得:
-
实时业务洞察雷达
-
自动化内容标签体系
-
智能决策支持基础
现在就开始构建您的关键词引擎,让数据真正开口说话!
在信息爆炸的时代,我们每天都会接收到大量的信息,而如何快速准确地从这些信息中提取出关键词,对于我们理解信息、做出决策至关重要。为了解决这一问题,自动化关键词提取工具应运而生。
自动化关键词提取工具是一种基于人工智能技朧的工具,通过对文本内容进行分析和处理,自动提取出其中的关键词。这些关键词可以帮助我们快速了解文本的主题、重点内容,从而节省大量时间和精力。
自动化关键词提取工具的工作原理通常包括以下几个步骤:首先,对文本进行分词处理,将文本拆分成单词或短语;然后,通过词频统计等方法分析文本中的关键词;最后,根据一定的算法和规则,选择出最具代表性的关键词。
自动化关键词提取工具有很多优点。首先,它可以快速准确地提取出关键词,避免了人工提取关键词时的主观性和偏差性。其次,它可以处理大量文本,提高工作效率。此外,自动化关键词提取工具还可以根据不同的需求和场景进行定制化设置,提供更加个性化的服务。
然而,自动化关键词提取工具也存在一些挑战和限制。首先,由于语义理解的难度,工具可能会出现误判或漏判的情况。其次,对于特定领域或行业的文本,工具的准确性可能会受到影响。此外,自动化关键词提取工具的算法和模型需要不断更新和优化,以适应不断变化的信息环境。
总的来说,自动化关键词提取工具在处理大量文本信息时具有重要意义。随着人工智能技术的不断发展和应用,相信这类工具将会越来越普及和完善,为我们提供更加便捷高效的信息处理服务。