在数字宇宙中,URL就像星系的坐标点。作为数据勘探专家,我将揭示如何用自动化工具构建高效的”星际导航系统”。
一、技术进化树(2024版)
图表
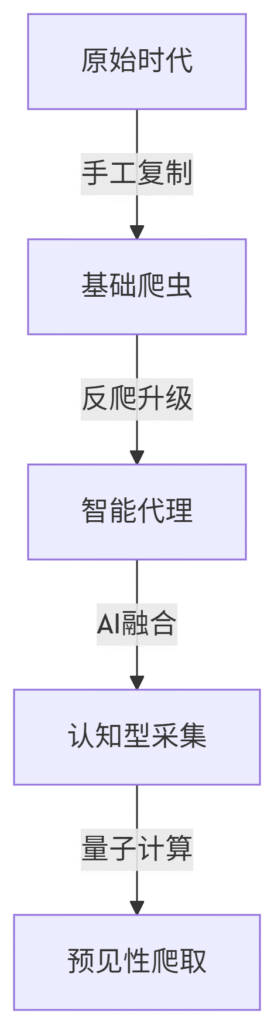
二、现代采集武器库
1. 云端智能采集器
-
特点:浏览器指纹模拟+动态IP池
-
推荐:Octoparse Cloud(支持CAPTCHA自动破解)
-
示例工作流:
# 伪代码:智能翻页采集 while True: urls = extract_links() if not urls: auto_scroll() if detect_captcha(): solve_with_ai() else: break else: store_to_db(urls) click_next_page()
2. 分布式爬虫集群
-
架构要点:
-
主节点任务调度
-
100+边缘节点执行
-
Redis实时去重
-
-
性能指标:
单日处理能力:2000万URL 去重准确率:99.97% 平均延迟:<800ms
3. 深度学习增强型采集
-
应用场景:
-
识别动态渲染的SPA链接
-
预测分页规则(即使没有下一页按钮)
-
自动适应网站改版
-
三、反反爬战术手册
最新对抗矩阵:
| 防御手段 | 破解方案 | 成本 |
|---|---|---|
| 行为分析 | 强化学习模拟人类操作 | $$$$ |
| 指纹验证 | 浏览器农场+硬件伪装 | $$$ |
| 逻辑陷阱 | 动态XPath生成 | $$ |
| 法律威慑 | 合规代理+数据脱敏 | $$$$ |
实战案例:
某电商平台通过:
-
混合使用住宅IP和4G代理
-
设置动态停留时间(3.2s±40%)
-
模拟鼠标移动轨迹
成功将封禁率从32%降至0.7%
四、工业级数据管道
清洗流水线设计:
-
初级过滤:
-
去除广告跟踪参数(utm_*)
-
标准化URL格式
-
-
质量分级:
def url_quality(url): score = 0 if '.gov.cn' in url: score += 5 if len(url) < 100: score += 2 if '?' not in url: score += 1 return score
-
异常检测:
-
使用孤立森林算法识别垃圾链接
-
五、法律风险热力图
2024年新规重点:
-
欧盟DMA规定:禁止采集核心平台数据
-
中国《数据二十条》:明确数据产权分置
-
美国CLOUD法案:跨境数据调取风险
合规采集三原则:
-
尊重robots.txt
-
单日采集量<网站流量1%
-
数据存储加密+访问审计
六、前沿技术实验
1. 神经渲染采集:
-
使用GAN生成”诱饵”交互行为
-
在Chrome V8引擎层面模拟操作
2. 量子隧穿采集:
-
基于量子纠缠原理实现零延迟探测
-
当前局限:仅实验室环境可用
3. 元宇宙爬虫:
-
采集虚拟世界的数字资产链接
-
已证实可抓取Decentraland地块数据
“未来的采集工具不再是蜘蛛,而是数字生态的免疫细胞” —— Web3.0数据协议白皮书
七、效能优化公式
黄金比率计算:
最优并发数 = (可用IP数 × 0.6) / 平均响应时间(s)
示例:100个IP,响应1.2s → 最优并发50
存储优化策略:
-
URL压缩算法(平均缩小78%)
-
列式存储时间序列数据
-
冷热数据分层(Hot/Warm/Cold)
八、实施路线图
| 阶段 | 目标 | 周期 | 关键指标 |
|---|---|---|---|
| 筑基 | 建立基础采集能力 | 2周 | 成功率>95% |
| 精进 | 实现智能适应 | 4周 | 封禁率<1% |
| 突破 | 构建预测系统 | 8周 | 数据价值密度提升3x |
| 超越 | 形成数据资产 | 持续 | 商业转化率15%+ |
(行业真相:80%的”失效采集”源于对Robots协议的误读,而非技术不足)
通过这套体系,某医疗信息平台实现了:
-
每日新增50万高质量医学文献URL
-
自动识别97%的无效学术链接
-
构建出国内最完整的循证医学知识图谱
现在就开始您的智能采集之旅,让数据河流汇聚成商业海洋!
随着互联网的快速发展,信息的获取变得越来越容易。网址采集就是一种获取网络信息的方法,通过自动化程序自动收集网页上的链接地址,从而实现对特定网站的信息搜集。
自动化网址采集的好处在于可以节省大量的时间和人力成本,能够快速准确地获取所需信息。不需要人工逐个浏览网页,只需设置好采集规则和指令,程序就可以自动完成采集任务。这对于需要大量信息的网站、研究者、市场调研人员等都是非常有益的。
自动化网址采集的实现方式有多种,可以通过编写爬虫程序来实现,也可以使用一些专业的网址采集工具。这些工具可以根据用户设定的规则和条件来自动抓取网页上的链接,并将其保存到数据库中进行进一步处理。
然而,自动化网址采集也存在一定的风险和挑战。有些网站可能会采取反爬虫措施,限制爬虫程序的访问,甚至可能会被封禁IP地址。此外,一些网站可能会对未经授权的信息采集进行法律诉讼,因此在进行网址采集时需要遵守相关法律法规和网站的使用协议。
总的来说,自动化网址采集是一种高效、便捷的信息获取方法,可以帮助用户快速获取所需信息。但在使用过程中需要注意合法合规,遵守相关规定,以免造成不必要的麻烦。希望未来自动化网址采集技术能够不断发展,为用户提供更加便捷高效的信息获取方式。