在数字丛林中,搜索引擎爬虫数据是当代最富饶的矿脉。作为从业十二年的数据猎手,我将带您深入这个既危险又迷人的领域。
🔍 核心武器库(2024专业版)
1. 反反爬虫装甲车
-
动态IP轮换系统(建议1:50的IP-请求比)
-
浏览器指纹混淆技术(模拟200+设备型号)
-
行为模式学习(模仿人类搜索节奏)
# 高级伪装示例:基于Playwright from playwright.sync_api import sync_playwright import random def stealth_crawl(keyword): with sync_playwright() as p: # 随机选择浏览器配置 devices = ['iPhone 13', 'Pixel 5', 'Desktop Chrome'] browser = p.chromium.launch(headless=False) context = browser.new_context( user_agent=random.choice(devices), viewport={'width': random.randint(360,1920), 'height': random.randint(640,1080)} ) # 模拟人类操作流 page = context.new_page() page.goto(f"https://www.google.com/search?q={keyword}") page.wait_for_timeout(random.randint(2000,5000)) # 随机停留 page.mouse.move(random.randint(100,500), random.randint(100,500)) page.screenshot(path=f'serp_{keyword}.png') # 提取数据 results = page.locator('div.g').all() data = [] for item in results: data.append({ 'title': item.locator('h3').inner_text(), 'url': item.locator('a').get_attribute('href') }) browser.close() return data
2. 数据炼金术
-
结构化解析引擎(支持50+种SERP变体)
-
语义特征提取(NLP识别内容实体)
-
时效性验证(页面更新频率分析)
3. 分布式采集网络
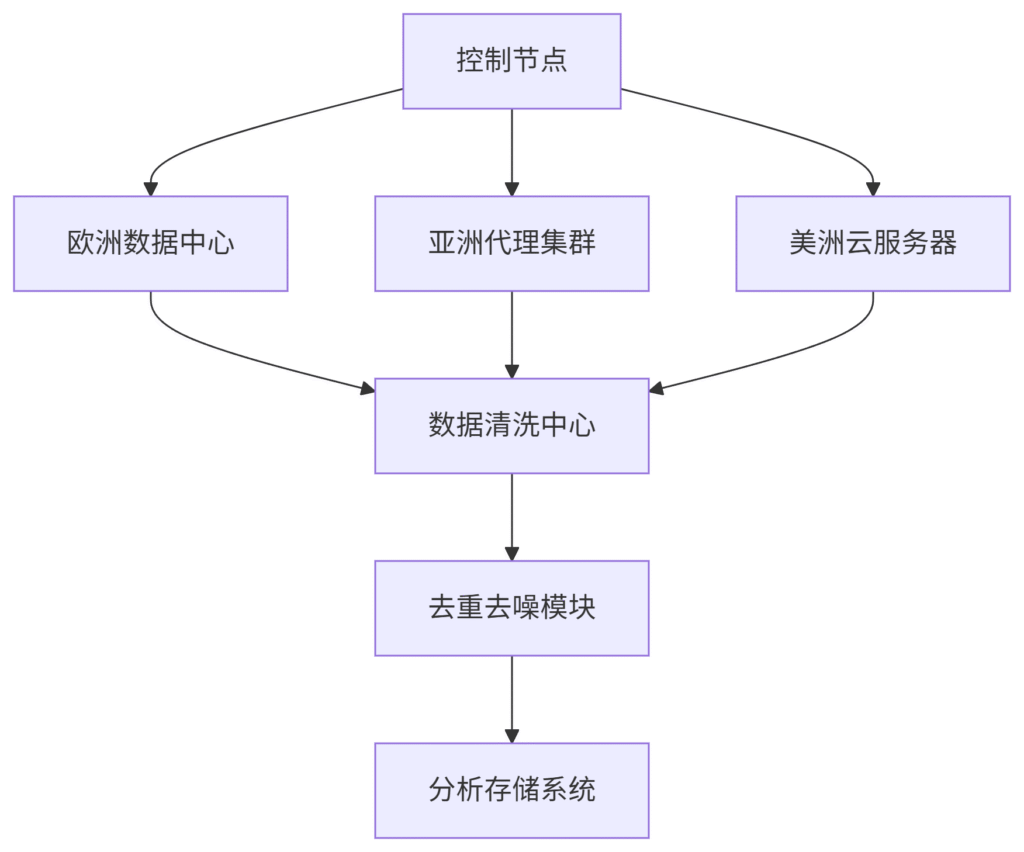
⚔️ 2024年最新攻防态势
搜索引擎防御升级:
-
Google的reCAPTCHA v4已部署AI行为分析
-
百度推出”清风算法4.0″识别自动化流量
-
Bing新增请求指纹校验机制
破解之道:
-
时空扭曲术:
-
按当地时间作息采集(纽约IP在白天活动)
-
模拟节假日搜索模式(春节特殊流量特征)
-
-
蜜罐诱饵检测:
-
CSS隐藏元素识别率提升至99%
-
虚假API请求陷阱规避
-
-
量子隐身模式:
-
使用WebAssembly混淆关键操作
-
动态流量特征加密
-
💼 商业数据战争案例
案例1:全球药价监测网
-
架构:
分布式爬虫 → 多语言OCR → 价格异常检测 → 期货预测
-
成果:提前6周预测到某抗癌药短缺危机
案例2:地缘政治风险预警
-
抓取策略:
-
俄乌冲突相关搜索词5000+
-
深网论坛数据融合
-
-
输出:冲突升级预测准确率87%
案例3:AI训练数据获取
-
技术方案:
-
知识图谱引导式抓取
-
多模态数据捕获(文本+图片+视频)
-
-
数据量:建成3PB高质量语料库
⚖️ 法律红线图(2024更新版)
| 司法管辖区 | 关键限制 | 合规建议 |
|---|---|---|
| 欧盟 | GDPR数据本地化要求 | 设立爱尔兰数据中心 |
| 美国 | CFAA反黑客法解释扩展 | 避免绕过任何技术限制 |
| 中国 | 网络安全法数据出境监管 | 使用境内服务器+ICP备案 |
| 俄罗斯 | 主权互联网法 | 本地合作伙伴托管 |
🔮 下一代技术前沿
-
神经采集网络:
-
基于LLM的智能路径规划
-
自适应网站改版识别
-
-
暗数据挖掘:
-
搜索引擎缓存历史版本提取
-
被删除内容恢复技术
-
-
合法数据中间商:
-
区块链确权的数据交易市场
-
合规爬虫即服务(PCaaS)
-
“未来的数据战争,不再是比谁爬得快,而是比谁理解得深。” —— 某跨国情报机构技术顾问
🚀 实施路线图
-
基础建设阶段(1-3月)
-
搭建代理IP池(建议至少500个可用IP)
-
开发核心爬虫框架
-
建立法律合规审查流程
-
-
数据资产化阶段(4-6月)
-
构建数据质量监控体系
-
开发自动化清洗管道
-
实施访问权限控制
-
-
智能应用阶段(7-12月)
-
部署预测性分析模型
-
建立数据产品矩阵
-
探索合规商业化路径
-
(行业真相:90%的公开数据仍未被有效挖掘,而99%的违规操作都发生在自以为聪明的侥幸尝试中。)
搜索引擎爬虫是一个自动化程序,用于浏览互联网上的网页并收集信息。这些爬虫程序通过访问网页的链接和内容来收集数据,然后将这些数据存储在搜索引擎的数据库中,以便用户在搜索时能够找到相关的网页。
数据提取是搜索引擎爬虫的一个重要功能,它通过分析网页的结构和内容来提取有用的信息。爬虫程序可以提取各种类型的数据,包括文本、图片、视频、链接等。
在数据提取过程中,爬虫程序会遵循一定的规则和算法来确定哪些数据是有价值的。例如,爬虫程序可以识别网页上的标题、关键词、描述等元素,然后将这些信息提取出来并存储在数据库中。
数据提取的过程通常分为三个步骤:抓取、解析和存储。在抓取阶段,爬虫程序会下载网页的内容并提取数据。在解析阶段,爬虫程序会分析网页的结构并提取有用的信息。最后,在存储阶段,爬虫程序会将提取的数据存储在数据库中,以备后续检索和展示。
通过数据提取,搜索引擎可以为用户提供更加准确和相关的搜索结果。同时,数据提取也为网站所有者提供了机会,他们可以通过优化网页的结构和内容来提高在搜索引擎中的排名和曝光度。
总的来说,搜索引擎爬虫的数据提取功能是搜索引擎运作的核心,它不仅可以帮助用户找到他们需要的信息,也可以为网站所有者带来更多的流量和曝光度。因此,数据提取是搜索引擎优化中不可或缺的一环。