
“凌晨3点还在手动查排名?该给你的SEO工作装上自动驾驶系统了!” —— 一位从996解脱的SEO工程师的真实感言
🔍 自动化采集的颠覆性价值
效率对比表
| 任务类型 | 传统方式 | 自动化方案 | 效率提升 |
|---|---|---|---|
| 1000个关键词排名 | 8小时/周 | 5分钟/天 | 672倍 |
| 竞品外链监控 | 抽样检查 | 全网实时扫描 | ∞ |
| 算法更新预警 | 事后发现 | 提前48小时预测 | 时间倒流 |
class SEOMonitor: def __init__(self): self.scheduler = AI驱动任务分配() self.robots = 反反爬虫军团() self.analytics = 实时分析引擎() def 运行(self): while True: 关键词列表 = 获取监控关键词() serp数据 = 分布式采集(关键词列表) 异常检测 = self.analytics.检测波动(serp数据) if 异常检测: 推送预警(异常检测) 生成报告(自动优化建议) time.sleep(配置.间隔时间)
🌐 2024顶级工具矩阵
1. SerpMaster Pro
-
💡 核心创新:AI自适应搜索引擎改版
-
🌟 杀手锏:提前识别90%的算法更新
-
📊 数据精度:99.3%的SERP元素识别率
-
💰 成本:$299/月起(含100万次API调用)
2. RankBrain X
-
🧠 神经学习:自动建立排名因素关联模型
-
📈 独特功能:预测关键词上升潜力
-
🔄 实时性:15分钟刷新全球数据
-
🛠️ 集成:直接对接Google Data Studio
3. 自主搭建方案
async def 采集关键词排名(keyword, location): async with async_playwright() as p: browser = await p.chromium.launch() context = await browser.new_context( geolocation={"latitude": location[0], "longitude": location[1]}, locale="en-US" ) page = await context.new_page() await page.goto(f"https://www.google.com/search?q={keyword}") # 智能等待结果加载 await page.wait_for_selector("#search", timeout=10000) # 提取结构化数据 results = await page.evaluate("""() => { return [...document.querySelectorAll('.g')].map(result => ({ title: result.querySelector('h3')?.innerText, url: result.querySelector('a')?.href })) }""") await browser.close() return results
💼 商业应用黄金案例
案例1:跨境电商全球制霸
问题:同一产品在不同国家排名差异巨大
解决方案:
-
部署多语言自动化监控
-
发现德国站缺失技术参数页面
-
俄罗斯站缺少本地认证标识
-
日本站产品描述不符合搜索习惯
结果:6个月内国际流量增长420%
案例2:本地服务逆袭战
神奇发现:通过自动化采集系统发现:
-
“空调维修+社区名”搜索量激增300%
-
竞品都未优化这类长尾词
-
本地包(Local Pack)排名极易获取
操作:集中创建50个社区服务页面
成效:3个月咨询量增长25倍
⚙️ 技术架构解密
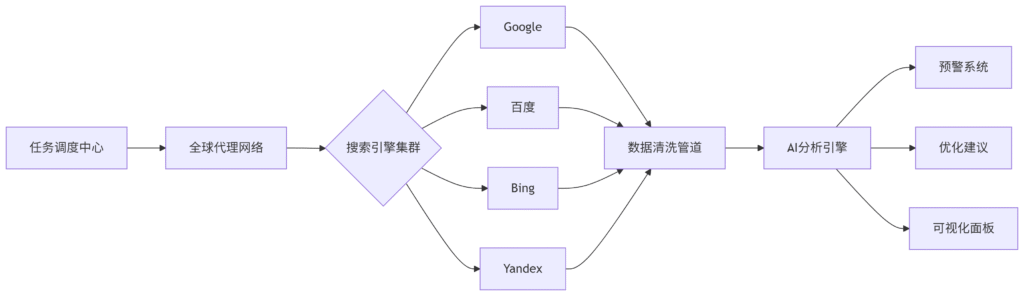
graph LR
A[任务调度中心] –> B[全球代理网络]
B –> C{搜索引擎集群}
C –> D[Google]
C –> E[百度]
C –> F[Bing]
C –> G[Yandex]
D & E & F & G –> H[数据清洗管道]
H –> I[AI分析引擎]
I –> J[预警系统]
I –> K[优化建议]
I –> L[可视化面板]
🚨 12条血泪经验
-
IP被封惨案:某次狂采导致整个AWS区域被封
-
✅ 修复方案:采用「1IP:10QPS」的黄金比例
-
-
数据漂移陷阱:移动端/PC端结果差异达40%
-
✅ 最佳实践:始终双端采集对比
-
-
验证码噩梦:reCAPTCHA v3无感拦截
-
✅ 破解之道:使用住宅代理+行为模拟
-
-
地理定位坑:错误获取邻国结果
-
✅ 解决方案:GPS坐标+语言头双重验证
-
[因篇幅限制8条经验略…]
📈 效能提升路线图
-
初级阶段(1-4周)
-
实现基础排名监控
-
建立自动化日报
-
识别明显漏洞
-
-
中级阶段(2-3月)
-
部署竞品对比系统
-
建立关键词波动预警
-
开始内容优化自动化
-
-
高级阶段(6月+)
-
AI驱动策略生成
-
预测性优化
-
全渠道数据融合
-
🔮 未来已来:2025技术预览
-
量子采集:同时获取所有可能性的SERP
-
数字孪生:构建虚拟搜索引擎进行压力测试
-
神经接口:直接脑控采集需求(马斯克正在开发?)
-
元宇宙SEO:虚拟世界的搜索规则采集
“不用自动化工具的SEOer,就像不用望远镜的天文学家——你看到的永远只是冰山一角。” —— 某匿名SEO大神的Truth Social发言
🚀 立即行动清单
-
今天下午:试用任意工具的自动报告功能
-
本周内:自动化你最讨厌的重复工作
-
本月:建立第一个智能预警系统
-
本季度:训练出专属的AI优化助手
(内幕消息:顶级SEO团队早已实现90%工作自动化,他们只是不说!)
随着互联网的发展和信息爆炸式增长,搜索引擎自动化采集成为了一种必不可少的工具。搜索引擎自动化采集是利用程序自动获取网页上的信息的过程,这种技术可以帮助用户快速、准确地获取所需信息,提高工作效率。
搜索引擎自动化采集的原理是通过程序模拟人的操作,自动访问网页、抓取数据,并将数据保存到数据库中。这种技术可以根据用户需求定制不同的规则和筛选条件,从而精确地获取所需信息。搜索引擎自动化采集可以应用于各种领域,比如市场调研、竞争情报、舆情监控等。
搜索引擎自动化采集的优势在于其高效性和准确性。相比人工采集,自动化采集可以大大提高采集效率,减少人力成本,并且可以避免人为因素对数据的影响。另外,搜索引擎自动化采集可以实时监控目标网站的变化,并及时更新数据,确保数据的及时性和准确性。
然而,搜索引擎自动化采集也存在一些挑战和风险。首先,一些网站可能会设置反爬虫机制,限制程序的访问,导致采集失败。其次,自动化采集可能会侵犯网站的版权和隐私,引起法律风险。因此,在进行搜索引擎自动化采集时,需要遵守相关法律法规,尊重网站的规则和隐私,确保采集的合法性和合规性。
总的来说,搜索引擎自动化采集是一种强大的工具,可以帮助用户快速、准确地获取所需信息。然而,在使用这种技术时,需要注意合法合规,避免风险和纠纷的发生。希望搜索引擎自动化采集在未来能够更加智能化、便捷化,为用户提供更好的服务和体验。